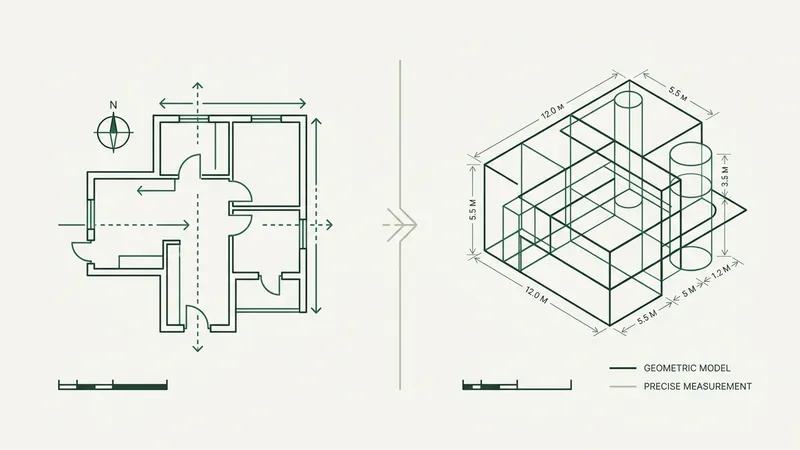
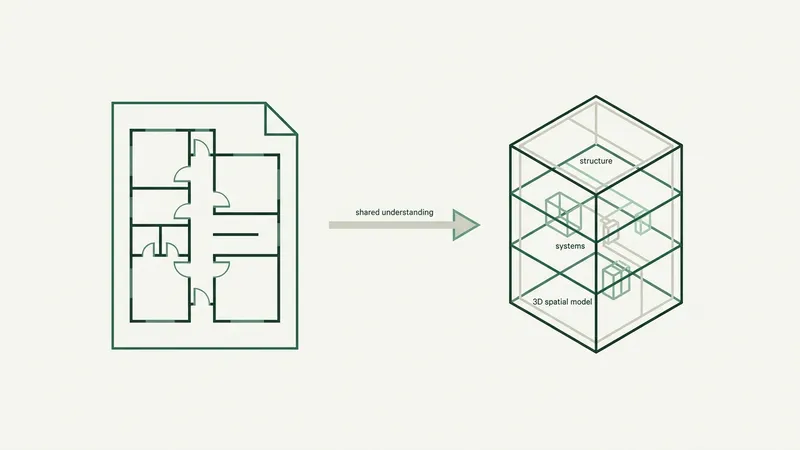
A preconstruction lead at an ENR top-50 electrical contractor sent me a screenshot last month. He’d asked a general-purpose AI assistant to count the lighting fixtures on a hospital sheet. The number that came back was confident, formatted nicely, and off by forty percent.
He wasn’t testing anything. He was trying to get a takeoff done before a bid deadline. The assistant didn’t know that hospital sheets use a regional symbol convention where a particular fixture type changes glyph between the architectural and the electrical sheet. It didn’t know that the legend on page three governed the count on page eleven. It didn’t know what a takeoff was, in the sense that a person who’d done a thousand of them would understand the question.
It gave him a number anyway.
I think about that screenshot every time an investor asks whether construction is really a vertical AI category or just a horizontal use case waiting for the next frontier model to clean up. The screenshot is the answer.
Horizontal wins

Horizontal AI works for a lot of things, and I want to be honest about that before I argue the other direction. Legal research is largely horizontal. The case law is public, the conventions are stable, and the tolerance for a small hallucination is real because a lawyer is going to re-read the passage anyway. Customer support is horizontal. The cost of being wrong on a refund question is a refund, not a building. Marketing copy is horizontal. The bar is “does this sound like us,” not “is the number exactly correct.”
In each of those domains, a general-purpose model wrapped in a thin product can serve a meaningful chunk of the work. The wrapper economics are reasonable. The model gets better every six months. The vertical specialization mostly happens in the prompt and the UI.
This is the playbook a lot of investors have internalized over the last two years, and it has worked. The instinct to apply it everywhere is rational. It just stops working the moment you cross into a domain where the data is private, the accuracy bar is uncompromising, and the workflow is one-shot. Construction is all three.
Private
The first thing to understand about construction drawings is that they were not designed for machines. They were designed for trained humans, and they’re full of choices that make sense only if you already know what you’re looking at.
Symbols change by region. A receptacle in Texas is drawn differently than a receptacle in Massachusetts. Abbreviations vary by trade and sometimes by firm. The legend that defines them lives on a different sheet than the one you’re counting on. Notes override drawings. Drawings override schedules. Schedules override notes, depending on what the addendum said. The whole document is an artifact of a hundred-year-old discipline that assumes the reader already knows it.
None of this is on the public internet. Sealed bid sets carry owner-level confidentiality. Subcontractor archives are governed by contracts that explicitly prohibit cloud handling. The U.S. Census Bureau estimates the industry generates roughly thirty billion pages of drawings, specifications, and submittals a year. Almost none of it shows up in Common Crawl. None of it is on GitHub. A general-purpose model has never seen most of what it would need to see to be useful.
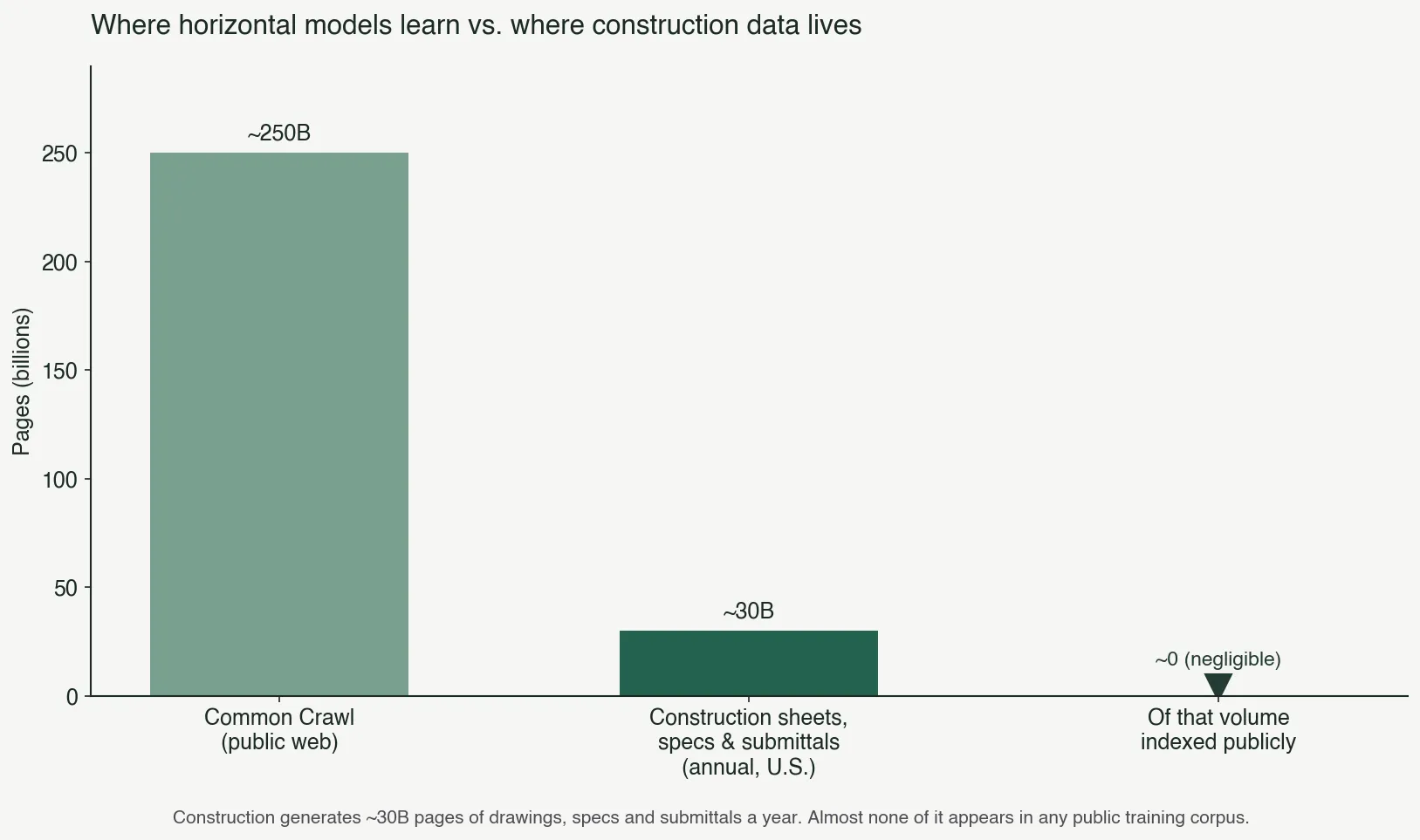
A wrapper can’t fix that with a prompt. The model behind the wrapper has the data it has. You can stuff a few examples into a context window and pretend that’s specialization, but the model still doesn’t know what it doesn’t know. On the easy pages it’ll guess plausibly. On the hard pages it’ll guess plausibly, and the estimator won’t know which is which until the bid is awarded and the building is half-built.
Accuracy
The second structural fact is that construction doesn’t tolerate “approximately right” the way most software domains do.
A takeoff that’s one percent off on a mid-sized electrical job is a fifty-thousand-dollar swing in the bid. If the bid is high, you don’t win the work. If the bid is low, you win the work and absorb the loss out of margin, which on a typical sub is six to nine percent. One bad takeoff erodes a quarter of a year of margin on that job. Two bad takeoffs and the GC stops calling.
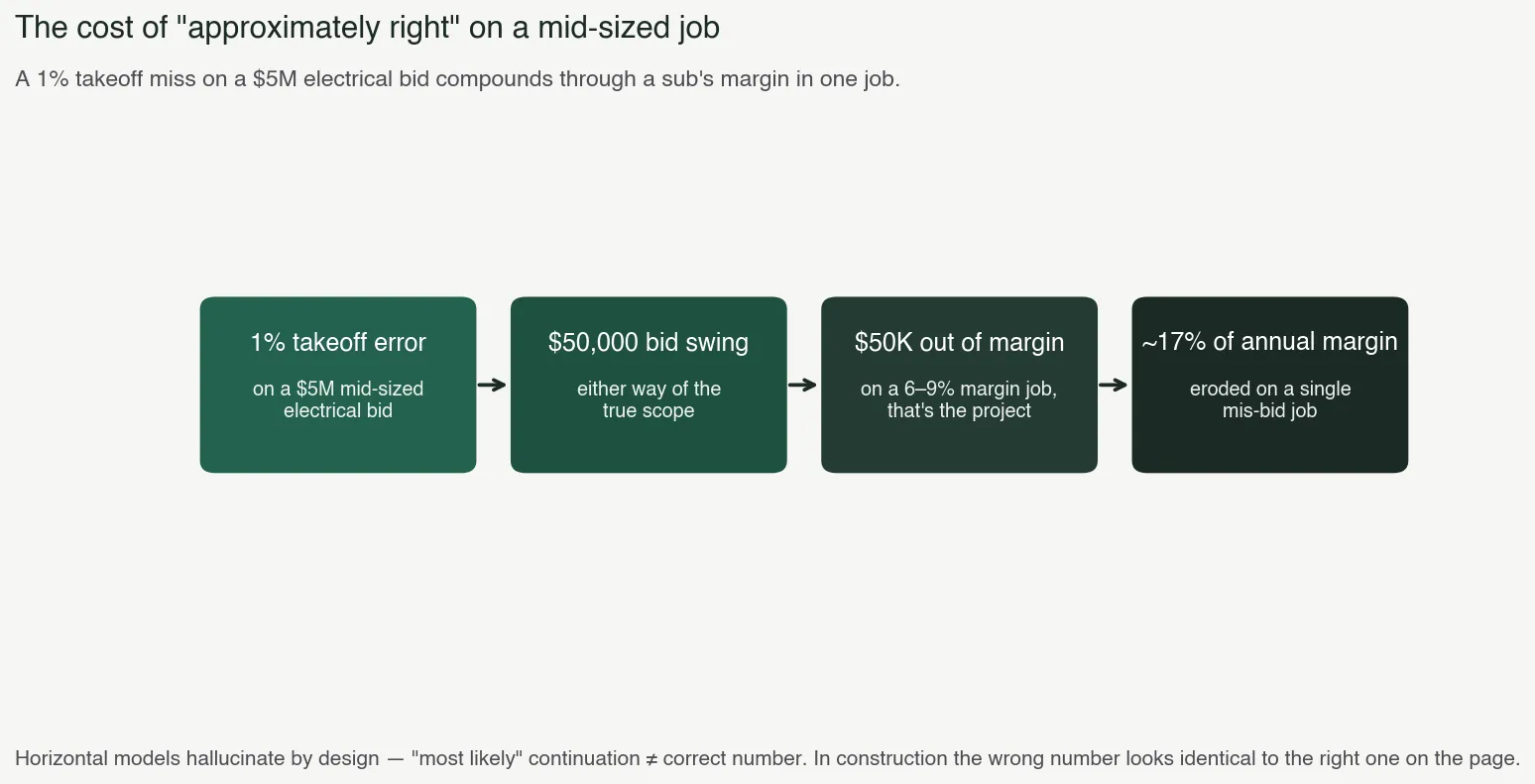
Horizontal models hallucinate. This is not a defect that’s about to be fixed by the next training run. It’s a property of how the architecture works. The model produces the most likely continuation of the input, and “most likely” is not the same thing as “correct” in a domain where the right answer is a number and the wrong answer looks identical to the right one on the page.
A general-purpose model that’s ninety-eight percent right on a takeoff is, for the estimator using it, indistinguishable from one that’s correct. Until the bid lands. Then it’s the worst tool in the office.
The accuracy bar in construction isn’t a benchmark. It’s a contract. You don’t get a second bid because your first one was close. You get a second bid because your first one was right and your relationship with the GC survived to the next project. A model that can’t carry that bar isn’t a slow version of a vertical product. It’s a different category.
Workflow
The third structural fact is the one I think is least appreciated by investors who haven’t worked in the industry. Construction workflows compound forward and don’t reverse.
Bids feed contracts. Contracts feed buyouts. Buyouts feed schedules. Schedules feed crews. Crews feed materials orders. Materials orders feed the build. By the time an error in the takeoff surfaces on the jobsite, it has propagated through six downstream decisions, each of which was made on the assumption that the input was right. Pulling it back costs money in every direction.
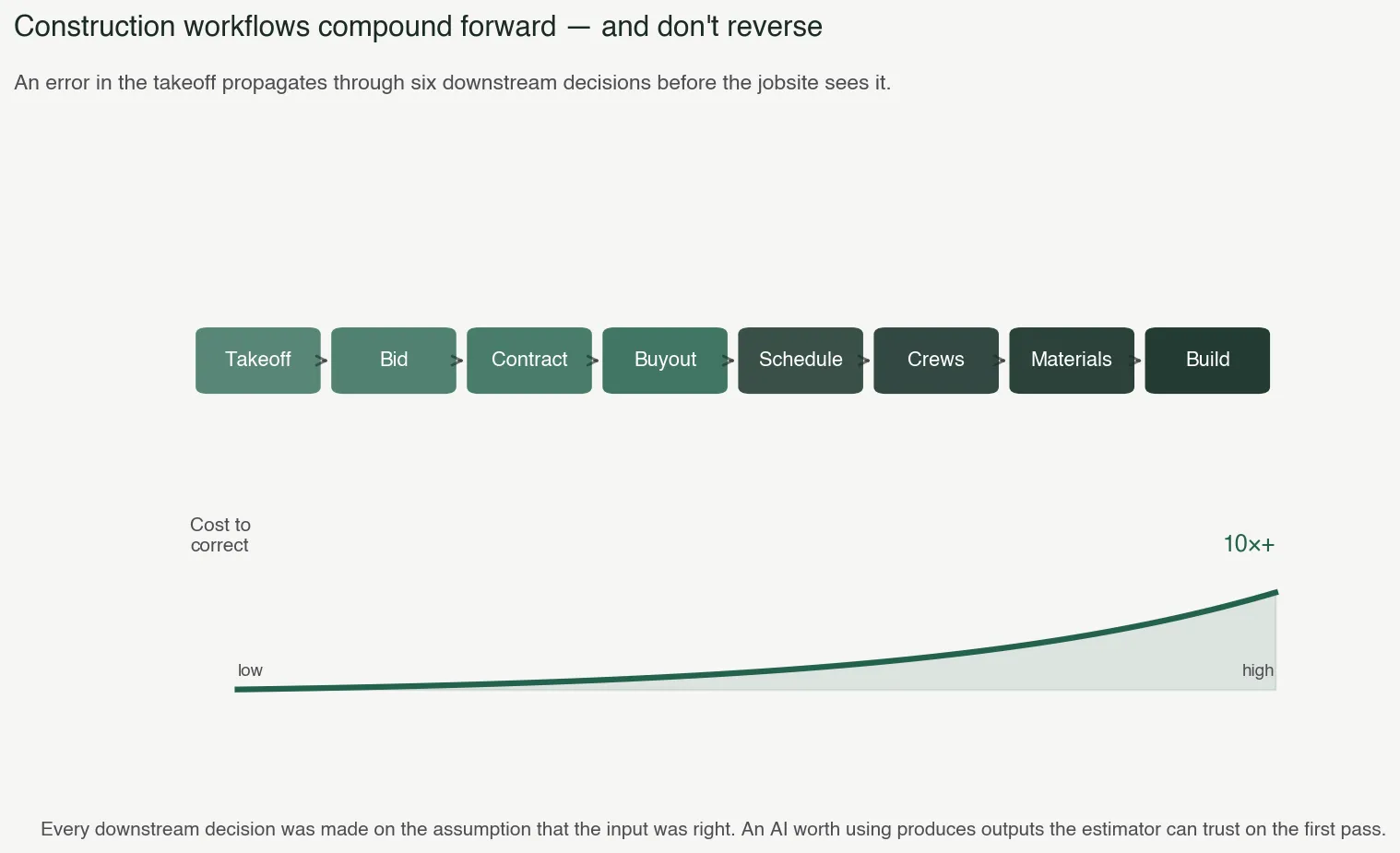
This is why “AI-assisted, human-in-the-loop” is a more complicated promise in construction than it sounds. The loop has a real cost. An estimator who has to double-check every number a chat interface produces is not faster than an estimator working alone. They’re slower, because they’re doing the work twice and carrying the cognitive load of guessing which of the model’s outputs to trust. The only kind of AI that helps in this workflow is one that produces outputs the estimator can rely on with the same confidence they’d give their own work, on the first pass.
That’s a higher bar than any general-purpose model meets today, and the gap isn’t closing along the curve horizontal labs are on. It’s a different curve.
Vertical
If the doctrine is that horizontal can’t win construction, the corollary is what vertical has to own. There are three things, and I’ve come to believe none of them are optional.

The first is the data pipeline. Owning the data means investing for years in surfacing the corpus that isn’t on the public internet, building the trust relationships that let real archives come in under NDA, and constructing the labeling layer that turns sealed bid sets into training signal without violating the confidentiality boundary. You can’t shortcut this with capital. The archives don’t yield to checks. They yield to time and to specific people inside specific GCs deciding you’re worth the relationship.
The second is the model. Owning the model means purpose-training, not prompting. It means choosing an architecture that compounds the data instead of stretching a general-purpose backbone to cover ground it was never trained on. The frontier labs ship every six months, and a vertical company can absorb that progress every time it lands. But absorbing progress is not the same as outsourcing it. A wrapper company is renting the brain. A vertical company is building one.
The third is the workflow. Owning the workflow means designing the product around the actual shape of an estimator’s day, not around a chat interface that assumes the user has time to compose a question. Construction software has died for twenty years on the same failure mode: the dashboard the estimator stops opening in week three. The product surface that survives is the one that lives where the work already is. For us, that’s Microsoft Teams. The point is that the workflow is not chat-shaped, and pretending it is gives up the only ground where adoption actually happens.
A vertical company that gets all three of these right has a stack that’s hard to copy from above. A horizontal wrapper has none of them. The wrapper can win the first demo. It can’t win the second project.
The next twenty-four months are going to sort the category along a single axis. On one side, companies that have spent the time, accumulated the corpus, trained the models, and earned the workflow placements the doctrine requires. On the other, companies that wrapped a chat interface around a general-purpose model and called it construction AI. The difference will show up in win rates, in renewal numbers, and in the question every preconstruction lead is starting to ask in pilots: what happens on the hard sheet, the one with the unusual symbol set and the addendum that contradicts the schedule. Wrapper companies can’t answer that.
We’ve been building toward this answer for four years, and I’d be lying if I told you we’ve gotten every piece of it right. We’ve killed approaches we thought were going to be the answer and weren’t. We’ve over-invested in some places and under-invested in others. The doctrine I’ve laid out here is what we’ve arrived at after enough mistakes to be embarrassed about, not what we knew when we started.
The screenshot the contractor sent me is the part that hasn’t changed. A horizontal model produced a confident answer that was wrong in a way only a construction person would catch. The estimator caught it. The next estimator at the next firm might not. The category will be won by whoever builds the model that doesn’t make that mistake in the first place, on the first pass, on the hard sheet. That’s the bet, and the next eighteen months will tell us how well we’ve actually held it.
Deepti Yenireddy is the founder and CEO of Boon AI.