By Deepti Yenireddy
I gave a 30-minute talk last week at Advancing Preconstruction in Phoenix. Track 4, the last slot of the afternoon, the one that usually empties out as people head for the exhibit hall. The room stayed full.
What didn't surprise me was the question I got asked at the booth afterward, in some version of the same sentence. "Do you actually believe an AI estimator can be on my staff by the end of next year?"
The talk was thirty minutes. The honest answer is the talk. So I'm writing it down here.
The line
I'll get the bold part out first.
By end of 2026, you will have your first AI estimator on staff.
Not a takeoff tool. Not a pilot. An estimator. A seat in your preconstruction org that owns a portion of the bid cycle end-to-end, with a name on the org chart and a number it's accountable to.
I know how that sounds to a room of VPs who've already been pitched four AI takeoff tools this quarter. So most of the talk wasn't about that line. Most of the talk was the work I had to walk through before the line was earnable.
Why nothing's worked
The first thing I told the room is something every estimator there already knew, but most vendors don't want to say. It's not that the AI is wrong. It's that the AI is right on the wrong things.
Most AI takeoff tools you've tried trained on architectural floor plans. Walls, doors, openings. They demo well because demos are run on architectural plans. Then you hand them a $50M mechanical package and the accuracy collapses, because ductwork isn't a wall and the model has never seen one labeled correctly. Or you hand it civil. Or structural. Or a panel schedule. The trades where bid risk actually lives are the trades nobody has trained on properly.
The second failure is architectural. Most vendors built one model per trade. Thirty-something siloed classifiers, each one learning in its own corner. What the model figured out about ducts doesn't help it read pipe. The flywheel never compounds.
The third is honesty. The industry talks about "98% accuracy" without saying what that means. Accuracy on which trade. Accuracy on a curated PDF, or on the redlined package you actually get on Friday afternoon. Accuracy as precision, or recall, or some marketing average. Nobody asks. So nobody answers.
I told the room: if a vendor doesn't talk about F1, walk away.
I spent a couple of slides on F1 because I think it's the single thing that would change how this industry buys AI in the next twelve months.
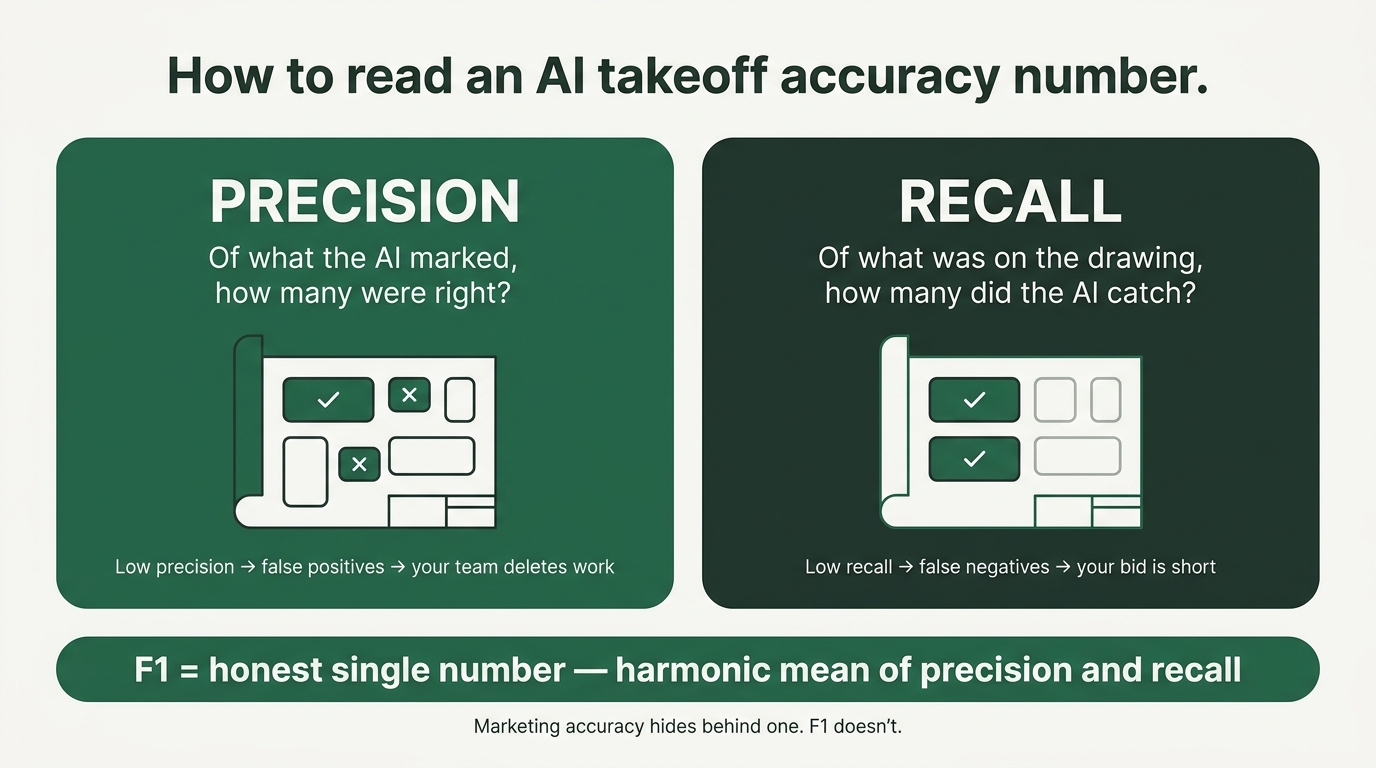
Precision is the question of, of the things the AI marked on a drawing, how many were actually there. Low precision means false positives. Your team spends Friday deleting work.
Recall is the question of, of the things on the drawing, how many did the AI catch. Low recall means false negatives. Your bid is short, and you find out the hard way.
F1 is the honest single number that balances the two. It's the harmonic mean — it gets dragged down by whichever side is weaker. There's no hiding behind it. It's the metric you'd ask an engineer for. It's not the one you'll find on a marketing site.
"90% accuracy" is a marketing number. F1 is an engineering number. Always ask which one you're being shown, and always ask per trade. Floor-plan F1 of 0.95 means nothing if mechanical F1 is 0.40.
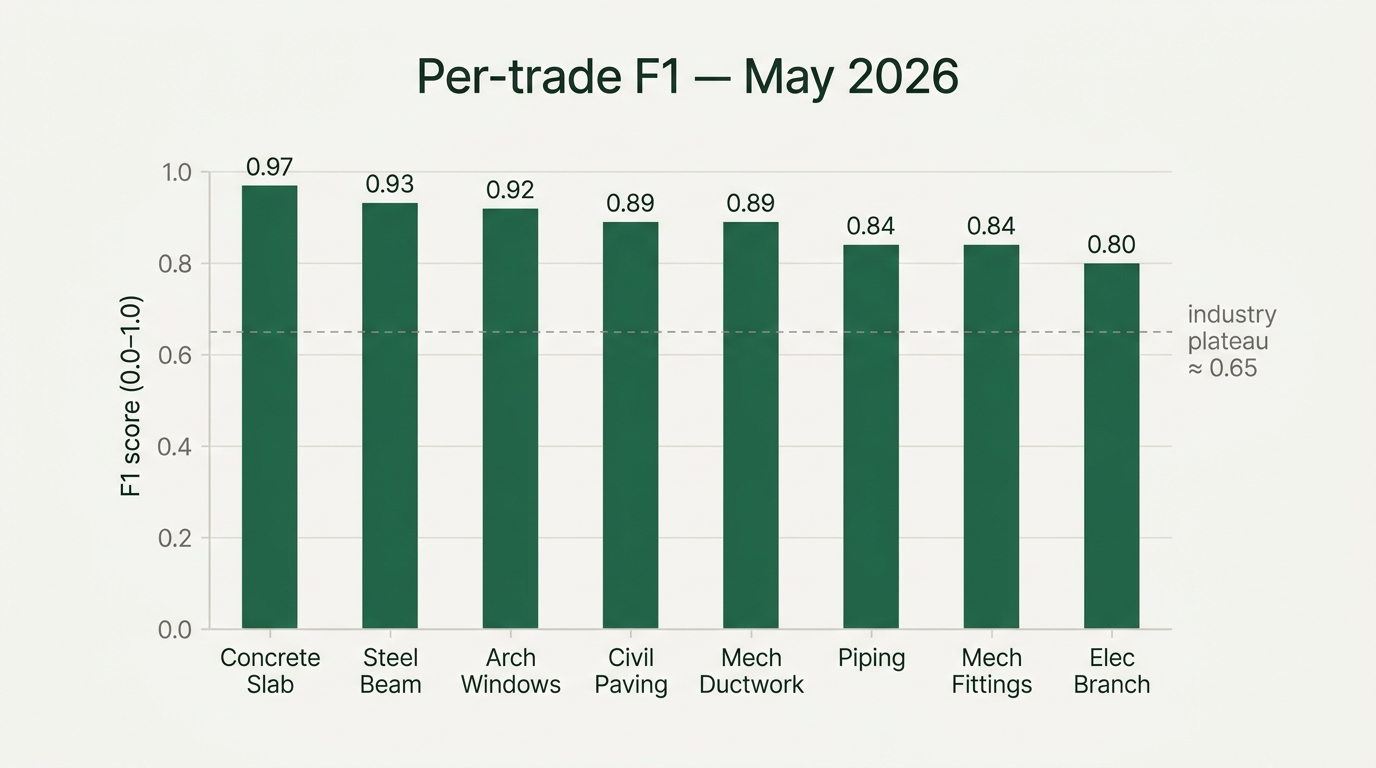
We publish ours. Every month. Per trade. As of the day of the talk, electrical branch circuits sat at 0.80. Architectural windows at 0.92. Mechanical ductwork at 0.89, with the mechanical average climbing from 0.59 to 0.82 in a single month on the same underlying model — every trade got better because we re-trained the foundation, not because we added headcount. Piping centerline at 0.84. Steel beam centerline at 0.93. Concrete slab at 0.97. The point isn't that the numbers are perfect. The point is that they're real, they move, and you can hold us to them. Full per-trade methodology here.
This was the slide where heads started nodding in the third row. Not because the numbers were dramatic. Because nobody had ever handed them the vocabulary to push back on a vendor's accuracy claim.
Kraken
Once you've named the failure modes, the architecture answers itself. The reason our F1 numbers keep climbing, and the industry's plateau, is that we built a foundation model instead of a bag of single-trade classifiers. We call it Kraken. One body, many arms, each arm has its own brain.
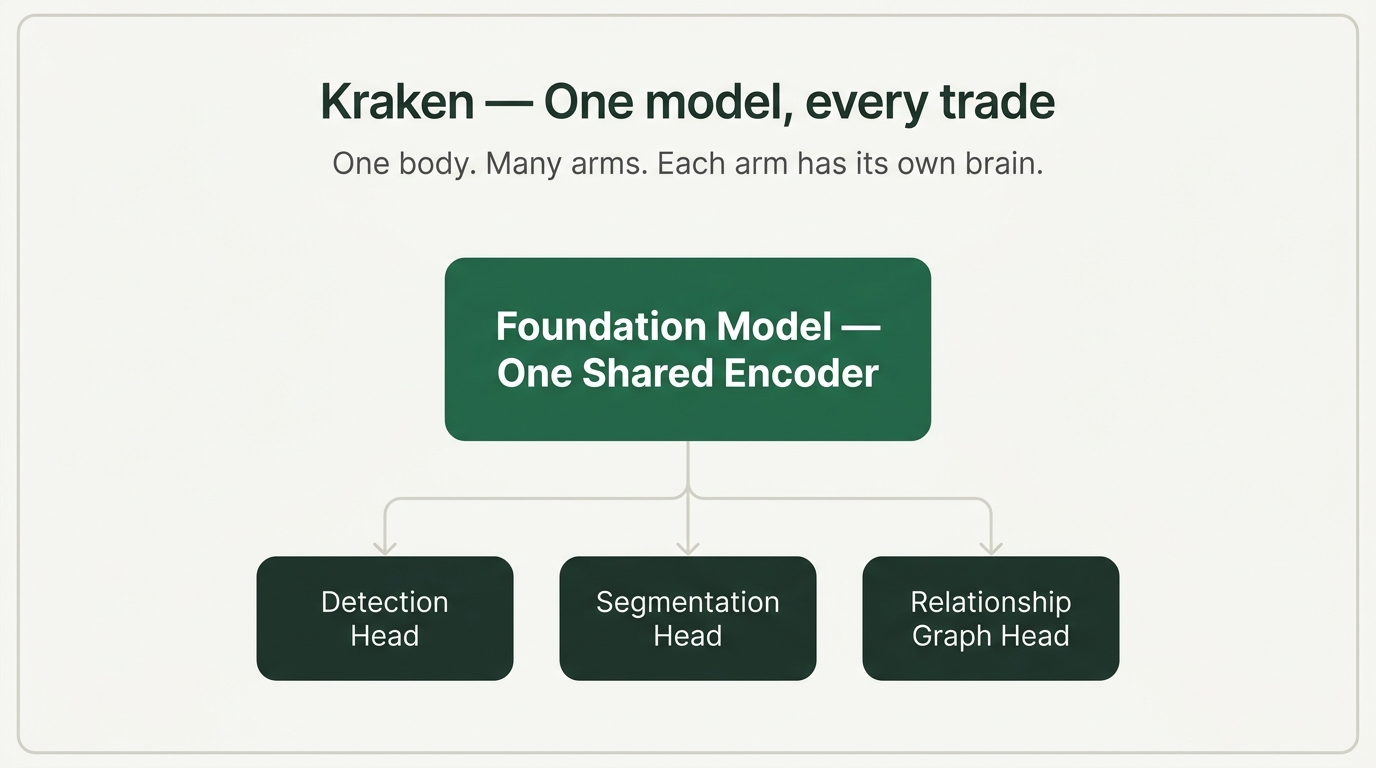
One body means one shared foundation model, trained on every trade's labeled drawings. Architectural, MEP, structural, civil, all going through the same backbone. The arms are trade-specific heads: detection, segmentation, the relationship graph that connects elements across drawings and specs. The body is shared.
What compounds is the cross-trade learning. What the model learns about wall labels improves duct routing. Pipe segmentation makes clash detection sharper. Every new labeled drawing improves every trade, not just its own. Same lesson as GPT-4 versus thirty-something small classifiers. Same lesson as Tesla's end-to-end vision stack versus thirty-something perception modules. Construction is the next domain where the foundation model wins.
I called this Frontier Spatial Intelligence on stage, on purpose. Spatial intelligence is the framing Fei-Fei Li uses at World Labs. Frontier is the vocabulary the labs use for what's moving the field. I wanted the room to leave with a phrase that placed construction AI on the same shelf as the rest of the frontier work, not on the shelf labeled "industry-specific software."
Gandalf
Kraken is hard to demo. So I didn't demo it. I demoed what runs on top of it.
We call the agent Gandalf. Kraken reads the drawings. Gandalf does the job.

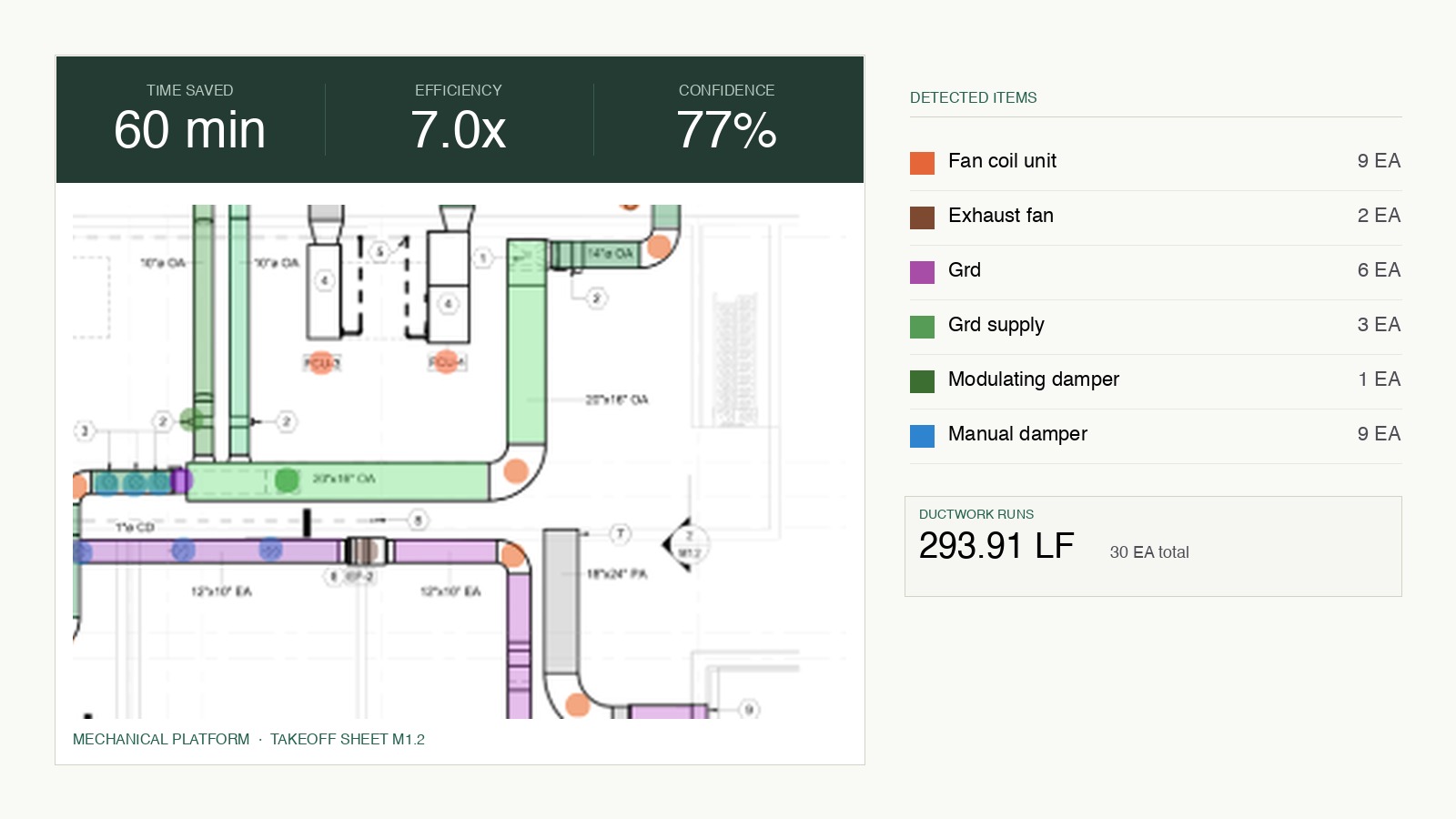
The video I played on stage was a real bid package, with the customer's permission, on a real Friday afternoon. The estimator pings Gandalf with a single Slack message — one link to the bid package, no setup wizard, no import pipeline. Gandalf reads the drawings and the specs. It flags a gauge mismatch between a mechanical drawing and the spec section governing ductwork — the kind of mismatch a human reviewer almost always misses because there's no reason to cross-check the two unless you're looking for it. It runs the takeoff on the three trades that drive cost on this package: ductwork, electrical, and flooring with finish-schedule attribution. Every number traces back to a region on a drawing. Click any quantity and the plan view lights up the polygon it was measured from.
Then Gandalf drafts the RFQ to the subs. The sub quotes come back, Gandalf lays them side by side, flags two scope gaps in the lowest bid, and recommends the apparent low with reasoning attached. Then Gandalf assembles the bid summary.

What the video shows takes Gandalf about seven minutes. The same scope, with a human estimating team, takes three weeks. Seven minutes versus three weeks isn't the headline I want anyone to walk away with. The headline I want is the audit trail. Every number Gandalf produces is clickable down to the source. The bid is defensible to ownership, to the GC the sub is bidding into. That's the part that earns the seat on staff. Speed alone doesn't.
The seat
So the line again, with the work behind it.
By end of 2026, you will have your first AI estimator on staff.
What I mean is specific. Not an assistant an estimator clicks buttons on. Not a tool a senior estimator drives. An agent that owns a portion of the bid cycle end-to-end, the way a junior estimator owns a portion of the bid cycle today. Triage. Spec review. Takeoff. RFQ. Bid leveling. Bid summary. Submission and internal risk review stay human; nobody at Boon thinks otherwise. But the seven steps in between are agent work, and the human estimator moves up to the judgment calls that need them.

This isn't a forecast. It's already happening today, in production, with customers running this on scoped trades — electrical, mechanical, and concrete. The work between now and end of 2026 is breadth, not invention. The reason I'm willing to put a date on it is that I can see what's between us and that date. It's labeled data, customer rollouts, and the unglamorous engineering of making an agent reliable on real bid packages from real GCs. We do that work every week. We can count the weeks.
The AGC's annual workforce survey keeps making the same finding. The industry can't hire its way out of the estimating gap. Most firms can't fill the preconstruction roles they have open. Five years ago, AI takeoff tools were a productivity nice-to-have. Today, they're the only path to closing a workforce gap that's getting wider every year. The firms that pull this off in the next eighteen months are going to bid on work the rest can't staff. The firms that don't, won't.

I closed the talk on the line: "The estimator of 2027 already exists. Let's introduce you."
I held it on the room because I wanted to push back on the part of the AI conversation where AI shows up to replace people. That's not what's happening in our customers' offices. Estimators are doing more bids, on bigger packages, with more confidence, because the agent is taking the parts of the job they hated and giving them back the parts they were trained for. The desk at the end of a day on Gandalf isn't empty because somebody left. It's empty because the human is in a meeting with the GC having a conversation only a human estimator can have, while the agent runs the takeoff in the background. That's the seat. That's the company on staff at end of 2026.
I'm not naive about the gap between this and the average preconstruction org today. We have customers running this in production right now and we have prospects who haven't logged into our takeoff product once since signing the order form. The firms who internalize what's possible in 2026 get to plan around it. The firms who don't, won't.
Try it
The best argument I can make for any of the above is the agent running on your own bid package. Not ours. Yours.
Send us a real package on a trade where bid risk lives — mechanical, electrical, structural, civil — and we'll run Gandalf on it end-to-end and walk you through the output, every number traceable to a region on a drawing. If the F1 doesn't land where we said it lands, that's a useful answer too.
Try it on your drawings: getboon.ai/product-landing .
Deepti Yenireddy is the founder and CEO of Boon AI.