The industry trained 37 narrow models and hit a ceiling. We trained one foundation model. This is why that architectural choice decides the next decade of construction AI.
Our head of engineering, Victor, came into a Monday standup eighteen months ago with a spreadsheet and a face that told me something was about to be harder than I wanted it to be.
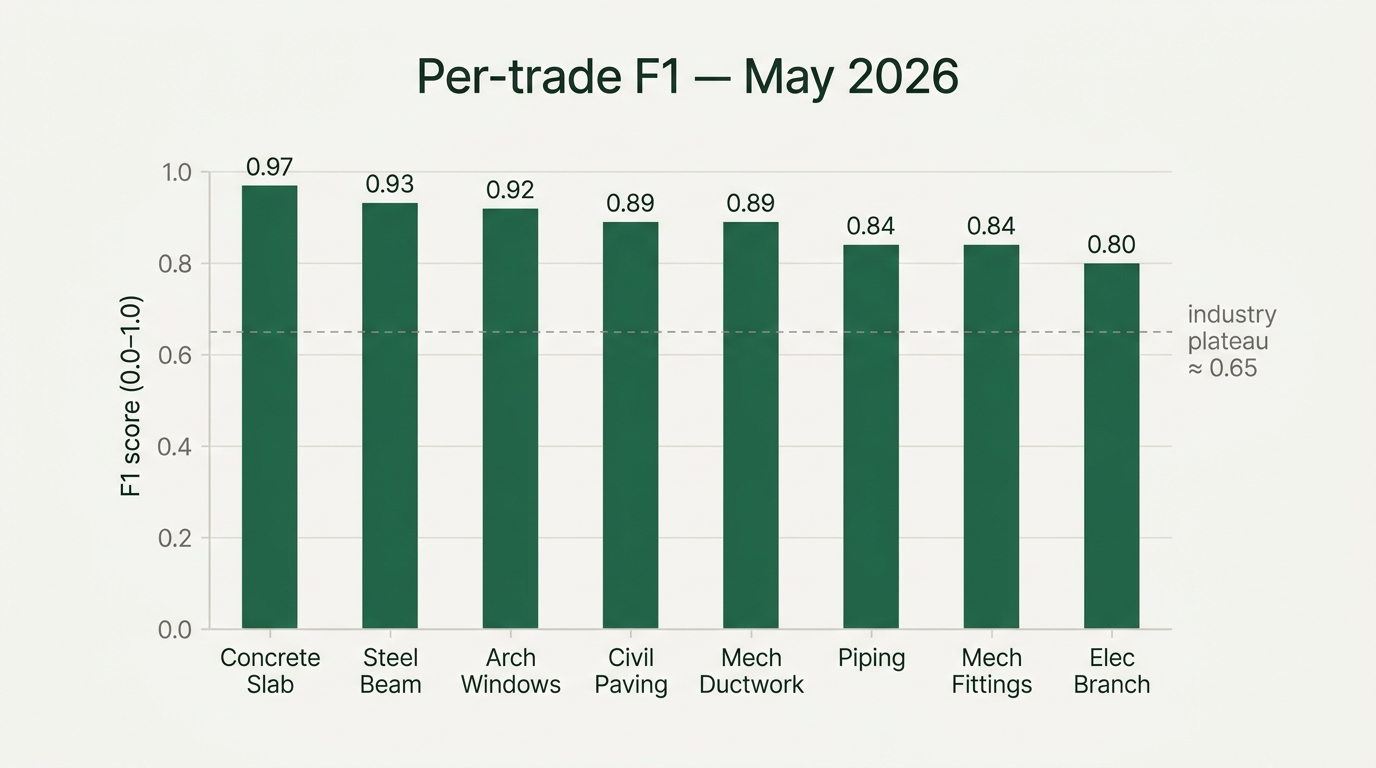
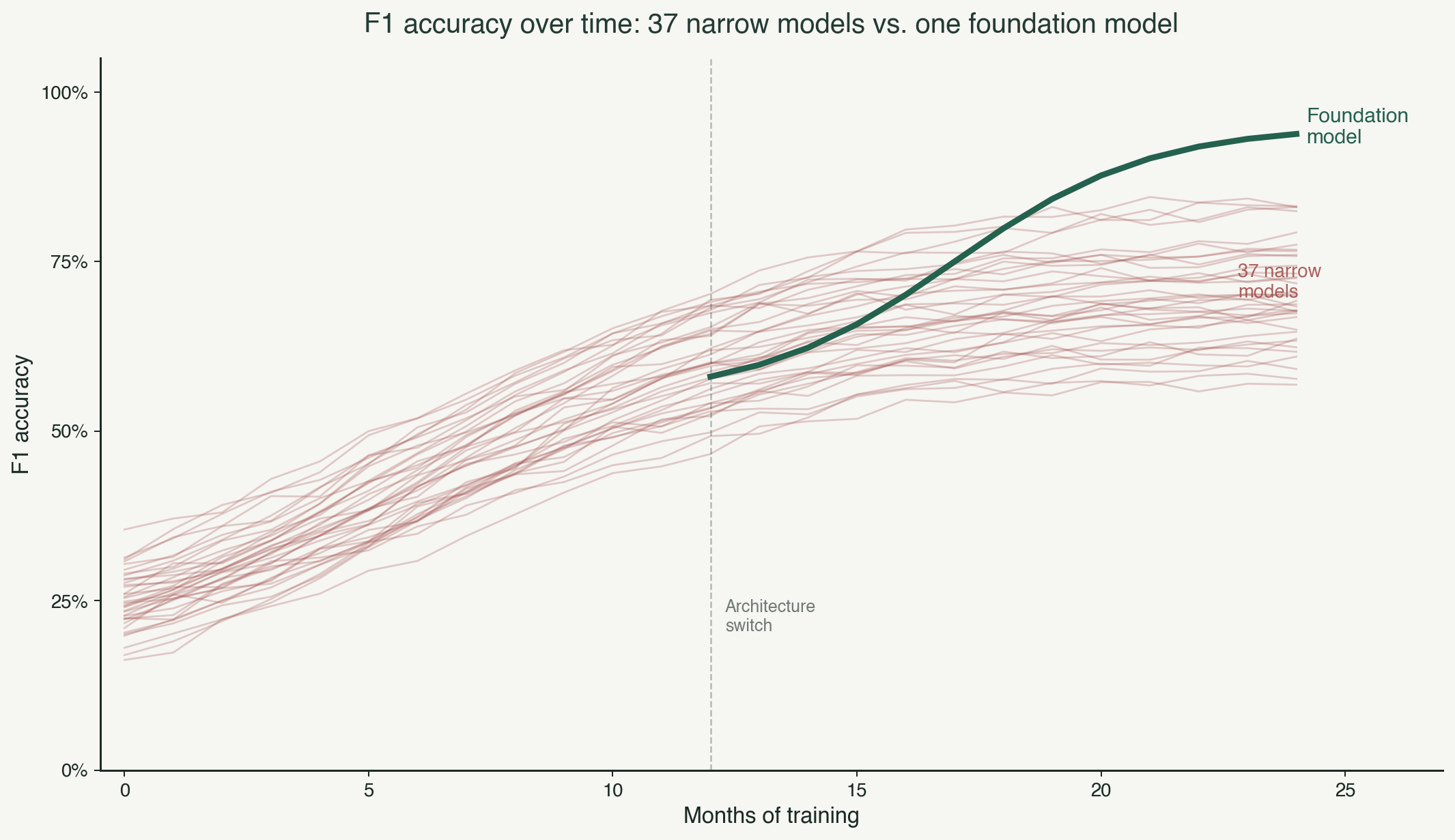
He had plotted the F1 accuracy of every trade-specific model we had shipped against time. Ducts, fittings, panels, receptacles, fire alarm devices, structural steel members, piping, joists, sprinklers, thirty-seven lines on the chart. For the first six months, every line climbed. More training data, better detection, faster improvements. The roadmap was working.
Then the lines flattened. Not all at the same altitude. Ducts at eighty percent. Fittings at sixty-five. Panels at eighty-two. Joists at seventy-one. Each one stuck at a different ceiling, each one stuck for a different reason, and each one refusing to move no matter how much trade-specific data we poured into it.
Victor looked at the chart and said, "We are building thirty-seven models that cannot talk to each other, and every one of them has already hit its ceiling."
That was the week we killed the zoo and committed to a foundation model for construction. What I want to walk through here is why that architectural choice is the one that decides which construction AI companies are still here in 2028, and why the thirty-seven-model vendors are structurally capped at a ceiling they can see but cannot cross.
The zoo architecture, and why it runs out of room
The default architecture in construction AI today is a zoo of narrow models. One model detects ducts. A different model detects fittings. A third detects electrical panels. A fourth detects fire alarm devices. A fifth detects structural steel. The glue between them is fragile pipeline code that hands bounding boxes between stages, runs per-class postprocessing, and assembles a takeoff at the end.
This is not a dumb architecture. It is a reasonable place to start. The first version of our own stack looked like this. You pick a trade, you collect labeled data, you train a model, you ship it, you move to the next trade. The work is tractable, the milestones are clear, the engineering is shallow.
It runs out of room for three specific reasons, and once you hit the ceiling, no amount of additional trade-specific data moves the number.
Siloed training has no cross-trade signal. A mechanical model trained on mechanical drawings never sees an electrical panel. An electrical model never sees a duct. But the geometric grammar of construction drawings, line weights, symbol composition, schedule formats, spatial arrangement on the sheet, is shared across trades. A siloed model has to rediscover this grammar per trade, with a fraction of the data it would have if it could share representation across the domain. It is training like a student who has to take the same algebra course thirty-seven times, once for each word problem.
Compound error at the seams. Every handoff between narrow models is a point of failure. The duct model hands bounding boxes to a fitting model. The fitting model did not train on the duct model's outputs and does not reason about connectivity. Errors compound across the pipeline. On hard pages (overlapping trades, unusual symbol variants, degraded scans), each model makes its own small mistake, and the assembly produces a takeoff that is structurally incomplete even when every individual model was reasonably accurate.
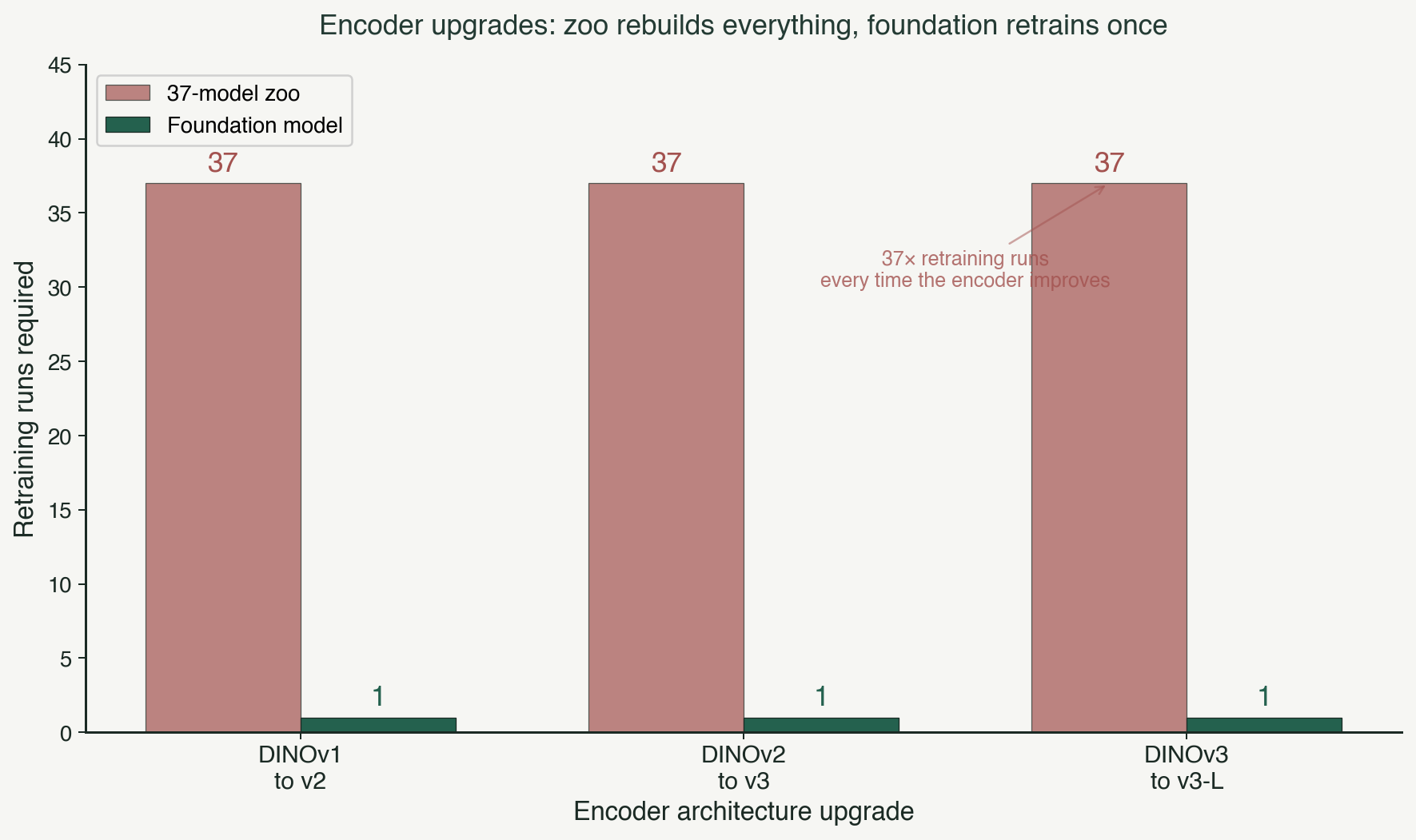
Every improvement requires N rebuilds. When the underlying encoder architecture improves (and foundation vision models have improved dramatically over the last two years), a zoo-based stack has to rebuild thirty-seven models to see the benefit. A foundation-model stack retrains the encoder once, and every head downstream gets the lift. The rate of improvement in a zoo is inversely proportional to the number of classes in the zoo. That is not a scaling law anyone wants to be on.
This is the structural ceiling Victor plotted. Each model hit its own local maximum. The cumulative system F1 plateaued in the mid-seventies. And the roadmap for getting past it was another thirty-seven training runs, thirty-seven data collection projects, thirty-seven bug-hunts, with no guarantee any of them would cross ninety-five.
The foundation-model bet: one encoder, many heads
The alternative architecture is straightforward to describe and very hard to build.
One shared encoder, trained on construction drawings across every trade we care about. On top of the encoder, trade-specific heads for dense segmentation, and a relational reasoning layer on top of those for cross-trade topology. The encoder learns the grammar of construction drawings once, at foundation-model scale. Every head inherits that grammar and specializes on top of it.
The picture is worth holding in your head: one brain that has seen every trade, with specialized outputs for each task. The brain is shared. The outputs are specialized. That is the architectural commitment.
What sits inside that brain is a self-supervised vision encoder, pretrained on a construction-specific corpus that took us three years to assemble. The corpus is the part we will not describe in this post, because it is most of the moat. What matters for the architecture argument is that the encoder is shared, the heads are specialized, and the relational layer reasons across them.
Why shared representation beats siloed training
Here is the empirical result that convinced us to kill the zoo.
When you train a single encoder on data from multiple trades simultaneously, the accuracy on every trade goes up. Not just the trade you added. Every trade. The representation the encoder learns from mechanical drawings makes it better at electrical. The representation it learns from structural makes it better at architectural. Cross-trade signal lifts the whole system.
This is transfer learning at the domain level, and it is the single biggest argument for the foundation-model architecture. Drawings across trades share more than they differ. They share:
- Geometric primitives (lines, arcs, symbol polygons, hatching patterns).
- Layout conventions (title blocks, sheet indices, legend placement, schedule formatting).
- Symbol grammar (repeat notations, schedule references, cross-sheet callouts).
- Scale and dimensioning conventions (how text relates to geometry, how dimensions are anchored).
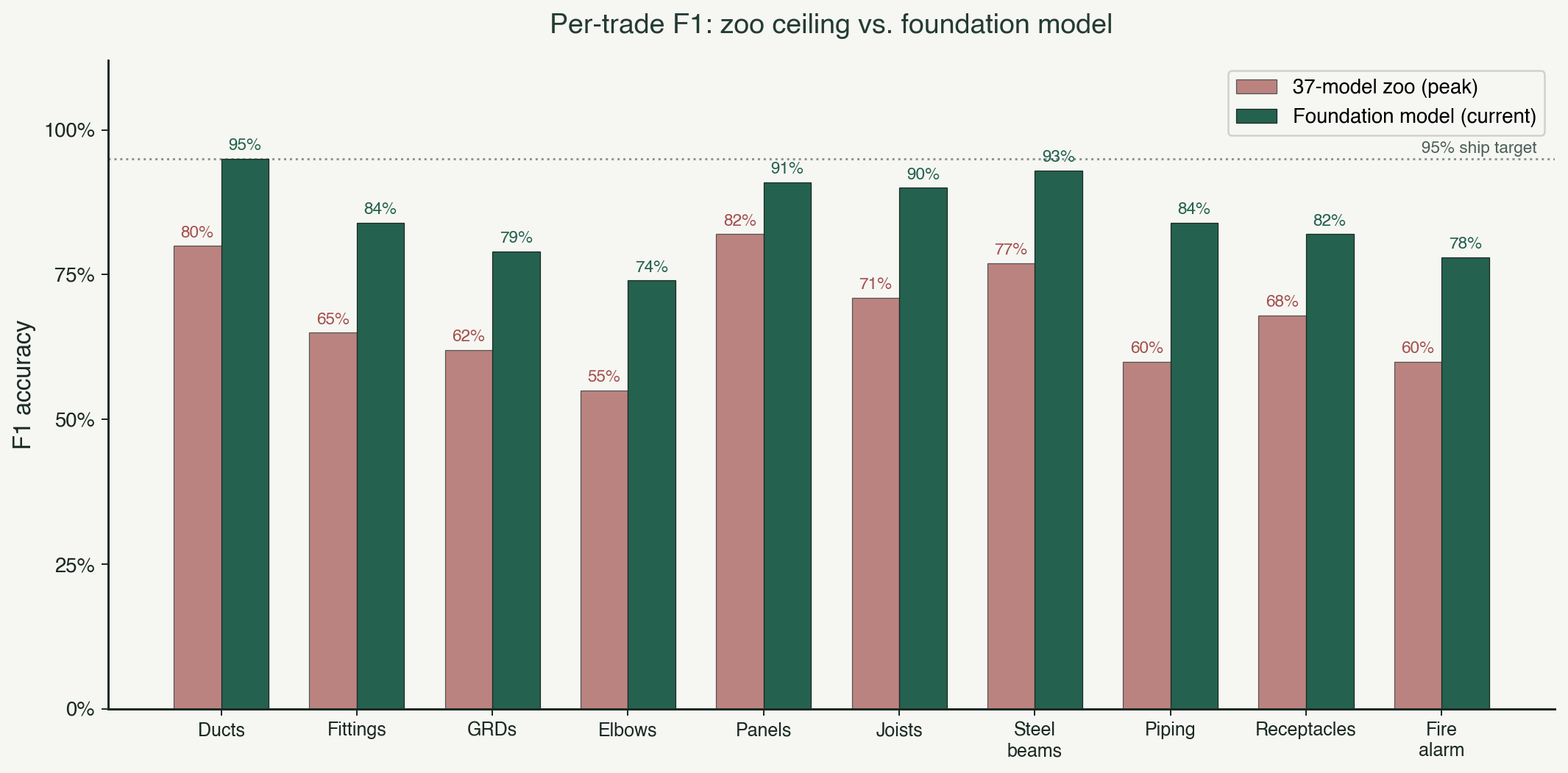
A siloed model trained only on electrical has to learn all of these from electrical data alone. A shared encoder trained across all trades learns them once, at the domain level, and every trade-specific head uses them. The result is that hard classes that were stuck in the zoo start moving again when the encoder has seen more data from elsewhere in the domain. Fittings at sixty-five percent in the zoo moves to eighty-five in the foundation model. Joists at seventy-one moves past ninety. Ducts at eighty crosses ninety-five. The ceiling Victor plotted does not exist in the new architecture, because the underlying representation is no longer starved.
There is a second-order effect that matters even more. When we add training data for a new trade, every existing trade gets slightly better. The foundation model accrues value every time any part of the dataset grows, not just when its specific head's data grows. That is a compounding dynamic. The zoo does not have it.
"We spent two weeks running the cross-trade transfer experiments. The electrical head got better when we added plumbing data. The structural head got better when we added mechanical. After the third week I stopped being surprised. That is just what shared encoders do. We had been giving up this effect for three years by training siloed." — a Boon ML engineer, during the architecture migration last year

The 37-model vendors are structurally capped, and that is the investor takeaway
I want to be specific about what "structurally capped" means, because it is the part of this thesis that matters most to investors.
A vendor with thirty-seven siloed models has three problems that are not solvable incrementally.
First, they cannot get transfer learning. Their accuracy ceiling per class is bounded by the data available for that class in isolation. In construction, the long tail of symbol variants and drawing conventions is enormous, and no single trade has enough labeled data to train past ninety-five on hard classes in isolation. The only path past ninety-five is shared representation. A siloed architecture does not have shared representation by definition.
Second, they cannot amortize encoder improvements. Every time the state of the art in vision encoders moves (and it has moved several times in the last eighteen months), a zoo-based competitor has to run thirty-seven retraining cycles to see the benefit. A foundation-model competitor retrains the encoder once. The rate at which the two architectures can absorb industry progress diverges, and the gap widens quarter by quarter.
Third, they cannot support relational reasoning. The graph between ducts and fittings, between panels and devices, between schedules and floor plans lives in the relationship between objects, not in the objects themselves. A zoo of classifiers has no shared representation to anchor these relationships. You can bolt heuristics on top (rule-based post-processing that says "every duct needs a fitting at each end"), but the heuristics are brittle and fail on exactly the hard cases where the value is highest. A foundation model with a relational head learns the topology in-distribution. The zoo cannot.
These three problems compound. The vendor stuck on the zoo architecture is three years into building a stack that cannot reach ninety-five F1 on the hardest classes, cannot absorb encoder progress without rebuilding everything, and cannot reason over physical systems without post-processing heuristics that break on hard drawings. The investor-relevant question is not whether they will catch up. It is whether they will rebuild their foundation before their cash runs out, and most of them will not.
According to a Stanford HAI analysis of enterprise AI deployments in 2026, vertical AI products built on modular narrow-model architectures show roughly half the year-over-year accuracy improvement of products built on shared foundation-model architectures (Stanford HAI 2026 AI Index Report ). This is consistent with what we observed internally when we ran the two architectures side by side. A zoo improves linearly. A foundation model improves in steps, and the steps compound.
The CVM and why "one model beats thirty-seven" is the right tagline
The Construction Vision Model is what we call our foundation model internally. It is one brain trained across every trade we support, with trade-specific outputs. It sees electrical panels, mechanical ducts, structural steel, and architectural details as variants of the same underlying geometric grammar. That shared representation is why it crosses the ceilings our zoo architecture hit, and why it continues improving every time we add any trade's data.
I am not going to publish specific per-trade benchmarks here. The trajectory is what matters for this thesis. Hard classes that were capped in the zoo are now moving again. Transfer from one trade's data to another's is measurable. Encoder improvements propagate across every head with a single retraining run. The architecture is doing exactly what the thesis predicted it would do.
The Boon bet, stated plainly, is that the vertical AI company that ships one construction foundation model ahead of the field wins the category. Not the one with the flashiest demo. Not the one with the biggest seed round. The one whose underlying architecture can absorb the next five years of industry progress and translate it into a better product every quarter.
The stake
One model beats thirty-seven is not a marketing line. It is a statement about which architecture compounds and which one caps. The companies that bet on zoos three years ago are now holding portfolios of models they cannot meaningfully improve without rebuilding. The companies that bet on foundation models are on a curve that bends every time the industry's underlying vision encoders improve, or a new trade's data comes in, or a customer's corrections land in the feedback loop.
The ceiling is real for the zoo. It does not exist for the foundation model. That is the line, and it is the line investors should be drawing when they evaluate the construction AI category.
Deepti Yenireddy is the founder and CEO of Boon AI.