Why the company that builds the best construction-specific training data wins the next decade.
In 2026, every software company calls itself an AI company. The pitch is always the same: “We fine-tuned a model. We built a wrapper. We added GPT to the workflow.”
None of that is a moat.
Models get commoditized. Wrappers get replicated. GPT wrappers built in a weekend get replaced in a weekend.
The thing that can’t be replicated is data. Specifically, the right data, structured the right way, for a domain so specialized that generic approaches fail on contact with reality.
Construction is that domain. And the data advantage being built here isn’t incremental. It’s structural.
Why Generic AI Breaks on Construction Drawings
General-purpose vision models (GPT-4o, Gemini, Claude) are remarkably good at understanding photographs, interpreting charts, and reading standard documents. They fail on construction drawings for a reason that isn’t obvious until you’ve spent years in the problem.
Construction documents aren’t images in the way AI models think about images. They’re dense, multi-layered technical compositions where the meaning depends on context that lives outside the page.
A symbol that means “duplex receptacle” on one firm’s electrical drawings means something entirely different on another’s. A hatch pattern indicating concrete in one region indicates insulation in another. Scale varies within pages. Legends contradict the symbols they’re supposed to explain. Revision clouds overlay the actual geometry.
No general model has seen enough of this to be reliable. The distribution of construction document variation is enormous, and almost none of it exists in the training sets of foundation models.
This is where proprietary training data becomes the moat.

Fig. 1: Why Generic AI Breaks — General-purpose vision models vs. Boon’s construction-trained vision
The Synthetic Data Factory
There are two ways to build a construction-specific training dataset.
The slow way: Collect real drawings from customers, manually annotate them, and accumulate data project by project. This works, but it’s constrained by customer acquisition speed, data sharing agreements, and annotation cost. At best, you build a dataset that covers the drawing conventions of the firms you’ve worked with. At worst, your model is overfit to your earliest customers’ particular drawing styles.
The fast way: Build a generator.
Boon’s synthetic data pipeline produces thousands of purpose-built edge-case blueprints per hour. These aren’t random noise. They’re engineered variations of real construction drawing patterns:
- Symbol placement variations. The same fixture type placed at unusual angles, in cluttered regions, near page boundaries, overlapping with annotations.
- Degraded quality simulation. Scanned originals, faxed copies, low-resolution PDFs, documents that were printed, marked up by hand, and re-scanned. The kind of drawings that show up on a Thursday afternoon when the bid is due Friday.
- Non-standard conventions. Architectural firms in different regions use different legend formats, different abbreviation standards, different line weights. The generator covers this variation systematically.
- Cross-trade contamination. Mechanical ductwork overlaid on electrical panels. Plumbing risers that share pages with structural details. The messy reality of real plan sets.
This synthetic pipeline does something that organic data collection cannot: it fills the gaps in the training distribution before customers encounter them. Instead of discovering that the model fails on a particular drawing style after a customer reports it, the generator has already created a thousand variations of that style for training.

Fig. 2: The Synthetic Data Factory — How Boon generates targeted edge-case training data at scale
The Flywheel Effect
Here’s what makes this compound.
Every real project processed on the Boon platform generates signal. Not just the drawings themselves, but the corrections estimators make, the symbols they confirm or reject, the areas they adjust, the scopes they define. This feedback is structured, labeled, and domain-specific. It’s exactly what training pipelines consume.
That real-world signal feeds back into the synthetic generator. The generator doesn’t just create random variations anymore. It creates targeted variations that address the specific failure modes observed in production. The training set gets smarter, not just larger.
The cycle:
- Production data reveals where the models fail.
- Synthetic generation creates training data targeting those failures.
- Retrained models perform better on those cases.
- Better performance drives adoption.
- More adoption generates more production data.
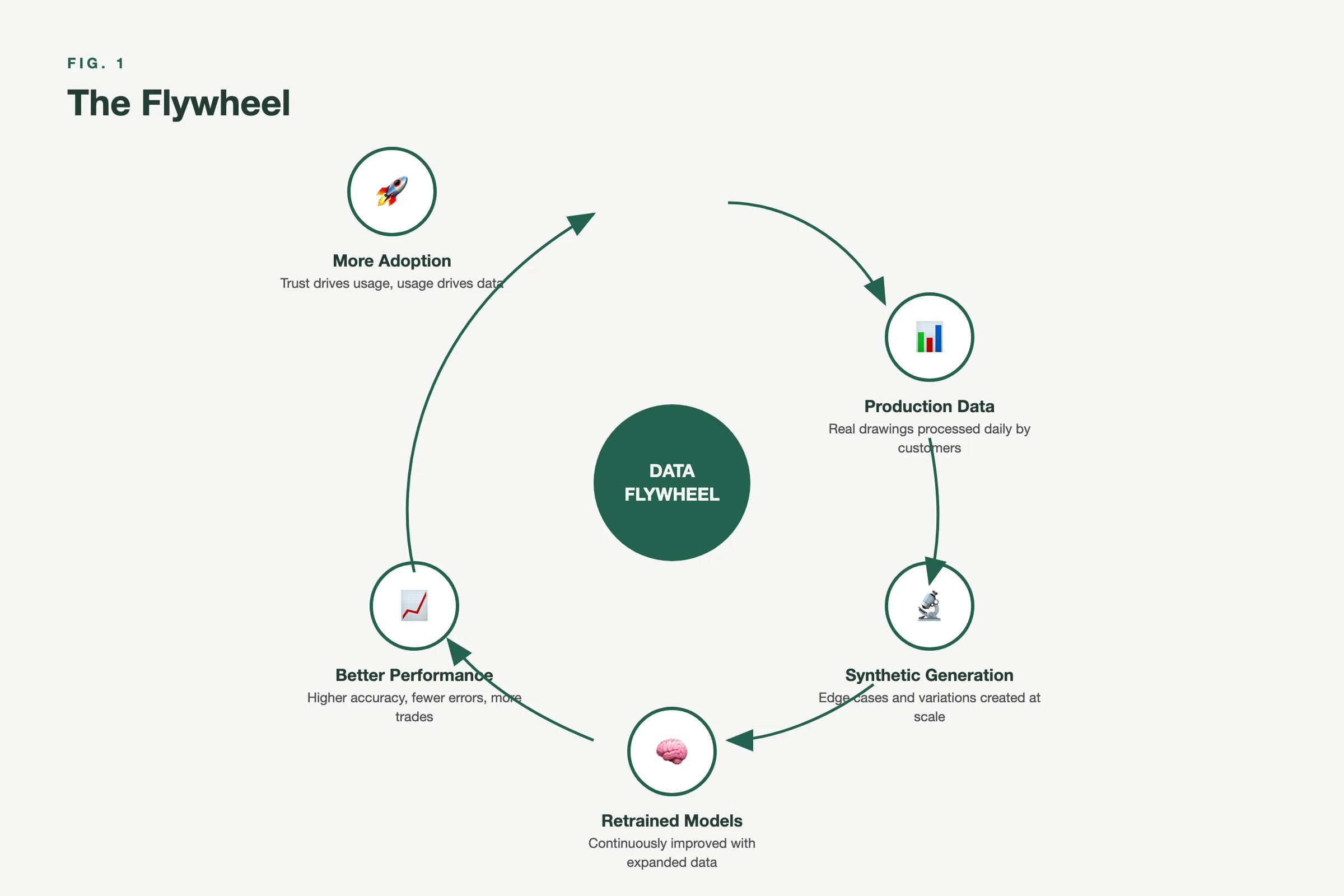
Fig. 3: The Data Flywheel — Each cycle compounds the data advantage
Back to step one.
This flywheel has no equivalent shortcut. You can’t buy this data. You can’t scrape it. You can’t generate it without understanding the domain deeply enough to know what variations matter. A competitor starting today would need to rebuild not just the generator but the years of production feedback that make the generator intelligent.
The Numbers
The scale of this data advantage is already significant, and it’s accelerating.
- Boon has ingested plan sets spanning billions of dollars in construction value across electrical, mechanical, structural steel, architectural, and civil trades.
- Our synthetic generator produces edge-case blueprints at a rate that no manual annotation team could match. The output is measured in the thousands per hour, covering symbol variations, quality degradations, and cross-trade scenarios that would take years to encounter organically.
- Every customer project processed adds structured signal back into the training pipeline. This isn’t passive accumulation. It’s an active feedback loop where corrections and validations from working estimators continuously sharpen the generator’s targeting.
The trajectory matters more than the snapshot. The dataset is growing in breadth (more trades, more drawing conventions) and depth (more edge cases per trade) simultaneously. Each month, the gap between this training set and what any newcomer could assemble widens.
Why This Matters for Investors
In deep tech AI, the question isn’t “do you have a model?” Everyone has a model.
The question is: do you have data that your model was trained on that nobody else can replicate?
For construction AI specifically, the answer depends on three things:
- Domain specificity. Generic vision models can’t do this. Construction-specific training data is required.
- Feedback loops. Static datasets become stale. Continuous production feedback keeps the data current and targeted.
- Generative capability. Manual annotation doesn’t scale. A synthetic pipeline that produces targeted training data at scale is the multiplier.

Fig. 4: Three Pillars of the Moat — Domain specificity, feedback loops, and generative capability
Boon has all three, running in production, with real customers, generating real feedback, compounding daily.
The moat isn’t the model. The moat is the data that makes the model work on construction documents that haven’t been drawn yet.
Boon’s synthetic data pipeline and production feedback loop create a training dataset that grows more valuable with every project processed. If you want to see how this translates to accuracy on your firm’s drawings, book a demo.