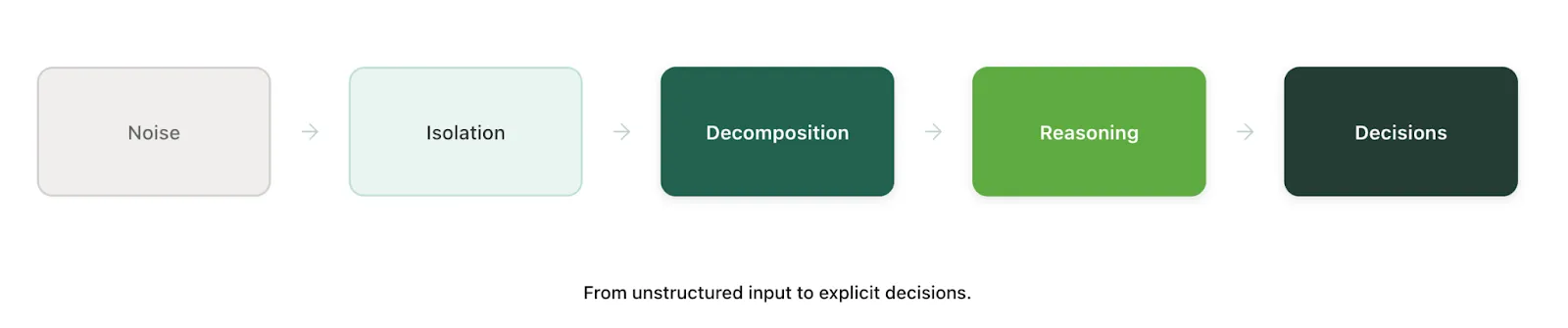
Construction documents don’t fail because they’re inaccurate.
They fail because they’re too dense to reason about holistically.
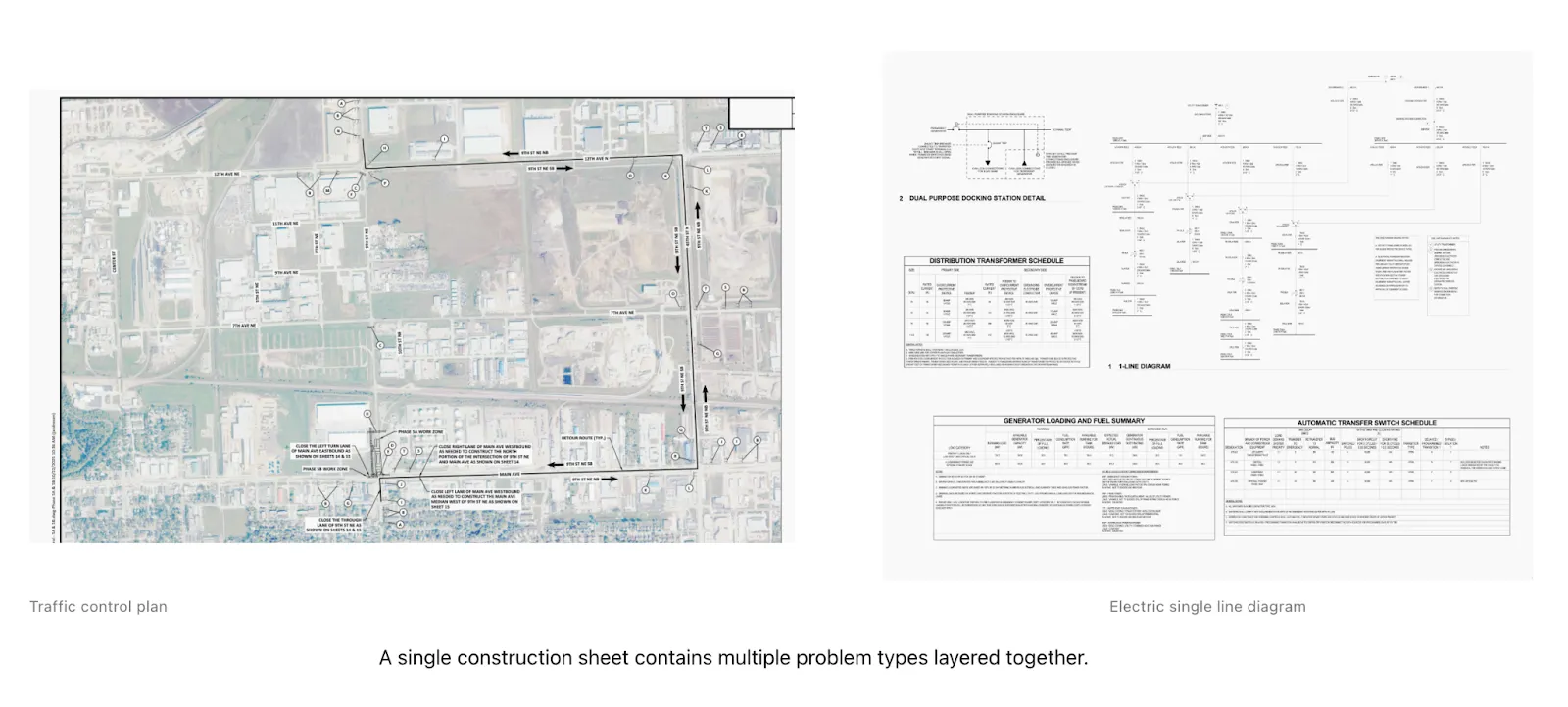
A single traffic control plan or single‑line diagram can contain geography, symbols, legends, schedules, annotations, stamps, revision notes, and legal text—layered on top of one another. The information you need is there, but it’s buried under 70–80% visual noise.
Historically, computer vision has treated this as a detection problem: run OCR or pattern matching across the full image and hope the signal survives.
It usually doesn’t.
We took a different approach.
The Core Insight: Vision Fails When Problems Aren’t Decomposed
When we began working with real construction diagrams at scale, accuracy wasn’t the primary bottleneck. Problem framing was.
These documents aren’t one task. They’re many:
- Identify which part of the page actually matters
- Separate legend from map from annotations
- Detect symbol classes
- Count and localize instances
- Reason about relationships between elements
Trying to solve all of this in a single pass guarantees brittle results.
So instead of asking a model to “understand the image,” we asked a simpler question:
What if the system could decide what to look at next?
That question led us to agentic vision.
Agentic Vision: Many Small Decisions, Not One Big Guess
With the release of Gemini 3, we gained a capability that made this practical:
fast, reliable visual decomposition at scale.
Within days, we re‑architected our vision pipeline around a multi‑stage, agentic approach:
- Isolate relevance
The system first identifies and suppresses noise—schedules, tables, stamps, extraneous text—using bounding boxes. - Crop intentionally
Instead of processing the full image, Gemini crops down to the region that actually contains the diagram of interest. - Decompose the task
Rather than detecting everything at once, the system breaks the problem into smaller units:- Identify symbol classes (A–T)
- Count instances per class
- Localize each instance
- Parallelize reasoning
Each sub‑problem runs independently. The system composes an answer instead of guessing one.
This is the difference between recognition and reasoned perception.

Parallelism in Practice: Bounding Boxes as Decisions
Once the system has isolated the relevant region, it stops treating the image as a single object.
Instead, it treats it as a set of independent, solvable questions.
Rather than asking “what symbols exist?”, it asks:
- How many A’s are here?
- How many B’s?
- Where are they located?
Each symbol class is processed independently and in parallel.
This does two things:
- It dramatically improves robustness on dense pages
- It makes failure modes explicit and debuggable

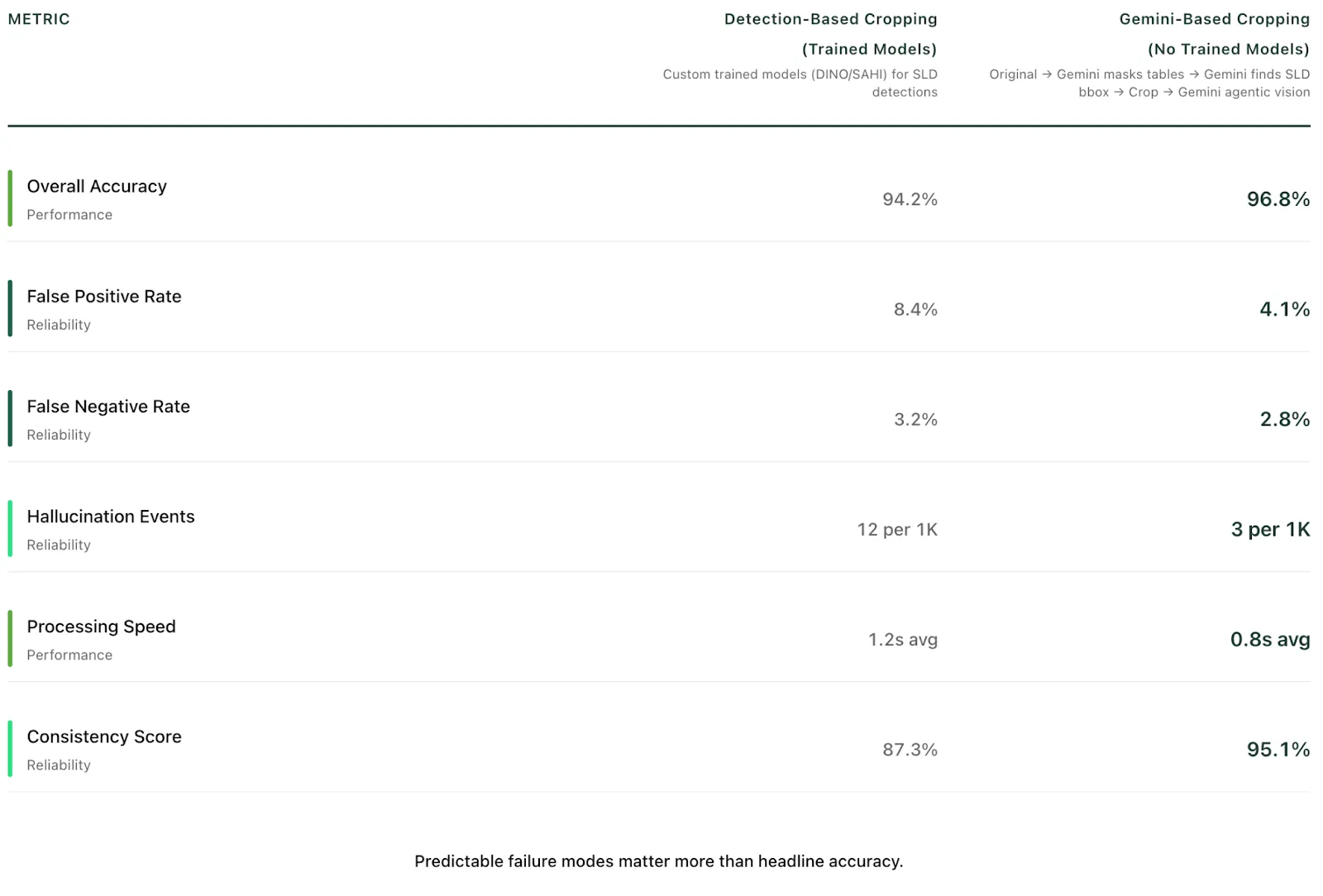
Results: Fewer Errors, Fewer Assumptions
Why the earlier approach failed quietly — and this one doesn’t
At a high level, this change wasn’t about making detection more accurate.
It was about avoiding blind spots before reasoning even begins.
In earlier versions of the system (V6), we relied on custom‑trained detection models to decide where to crop single‑line diagrams.
The process worked like this:
- Use trained models to detect equipment and panels
- Crop the diagram based on what those models detected
- Pass the cropped image into a reasoning step to infer connections
This approach worked when detections were perfect.
But when something was missed, the failure was silent.
If a piece of equipment wasn’t detected, it was cropped out entirely. And once it was gone, the system could not reason about connections to something it could no longer see. Missed detections upstream turned into missed connections downstream.
The system didn’t know it was wrong — it simply lacked visibility.
In the current version (V7), we removed trained detection models from the cropping path entirely.
Instead of asking models to find specific equipment first, the system now establishes global diagram context before any detailed reasoning happens.
The process now works like this:
- First, the system identifies and masks non‑diagram regions such as tables, notes, and title blocks
- Next, it identifies the boundary of the actual single‑line diagram
- The image is cropped to that boundary
- Only then does the system reason about panels and their connections
This changes the failure profile fundamentally.
As long as the diagram itself is present, downstream reasoning retains access to all relevant components — even when individual elements are ambiguous or difficult to classify. When the system fails, it does so in visible, inspectable ways rather than silently dropping information.
That’s why this version doesn’t just perform better in aggregate metrics — it behaves more predictably on real drawings.
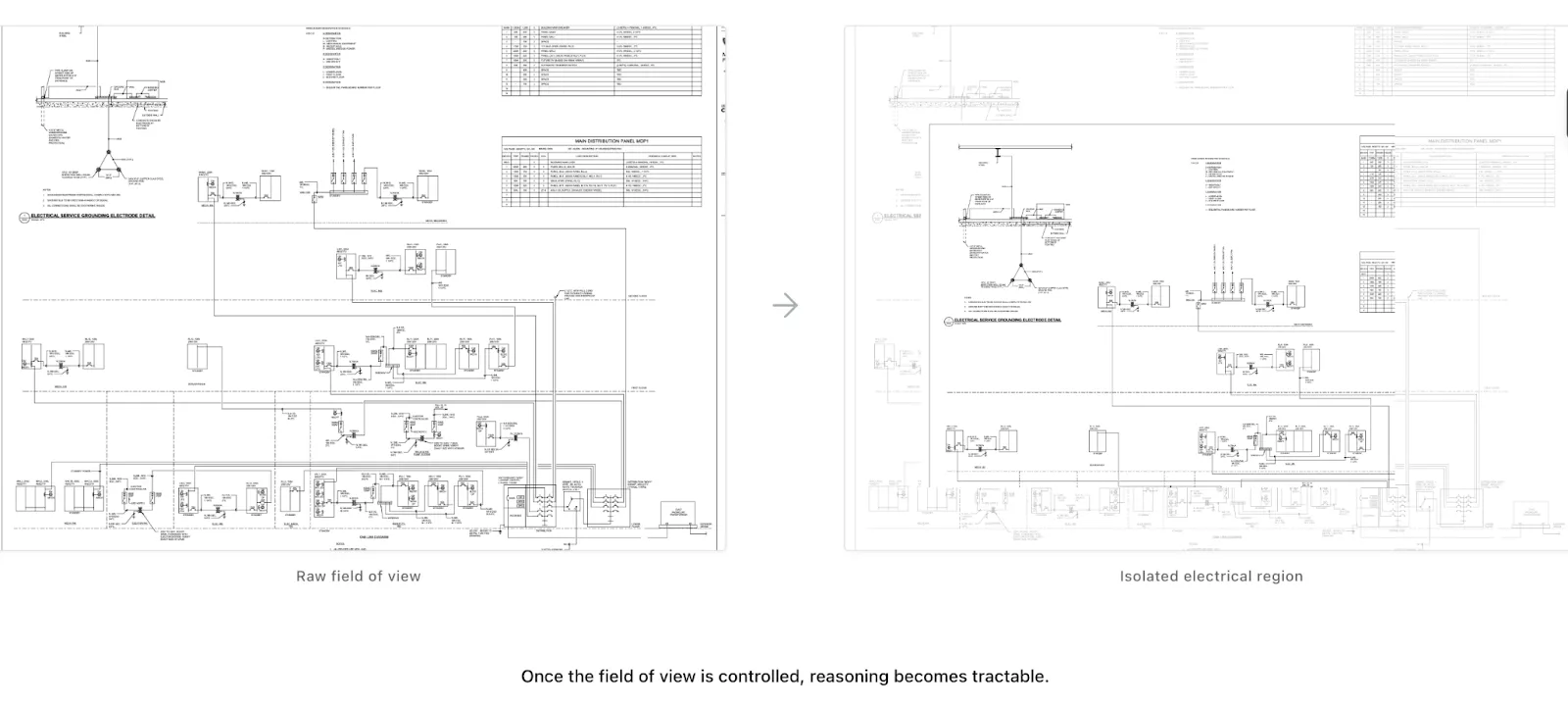
Beyond Detection: Reasoning About Structure
Detection is only the first step.
For single‑line diagrams, the real challenge isn’t identifying symbols—it’s understanding connectivity:
- Which panels connect to which
- How power flows
- Where boundaries and handoffs occur
Again, single‑pass approaches fail.
Our pipeline instead:
- Uses Gemini to isolate the SLD region
- Decomposes the diagram into smaller sub‑graphs
- Applies a reasoning model to infer connectivity
- Reassembles system‑level understanding from local decisions
This is not OCR.
It’s structured reasoning over visual primitives.
Why This Matters for Preconstruction
Construction documents are not static artifacts.
They are commitments.
Every missed symbol, misread annotation, or misunderstood connection eventually becomes:
- An RFI
- A schedule slip
- A field correction
- A margin hit
What agentic vision enables isn’t just better extraction.
It enables earlier clarity.
By decomposing vision into decisions, the system can surface:
- What is known
- What is inferred
- What remains ambiguous
That distinction is where real leverage lives.
A Different Way of Building Vision Systems
Agentic vision isn’t a feature.
It’s a stance.
It assumes:
- Complex documents cannot be understood in one pass
- Reasoning beats recognition
- Explicit uncertainty is better than silent confidence
Gemini 3 made this approach faster and more scalable.
Our architecture made it useful.
This is the foundation we’re building on.
More soon.