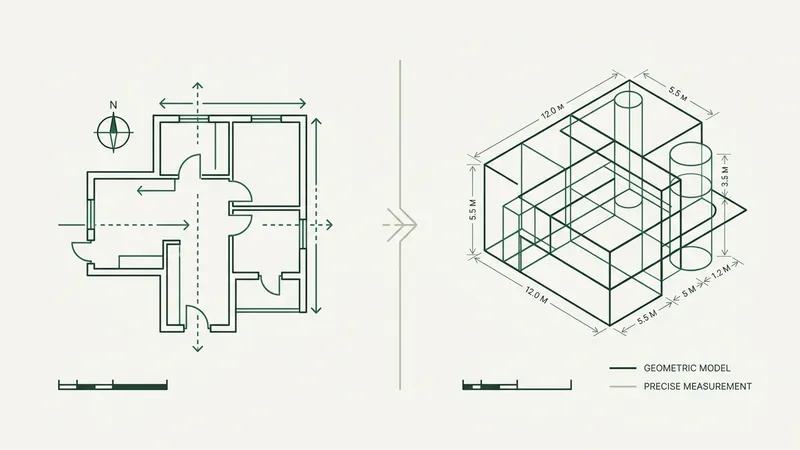
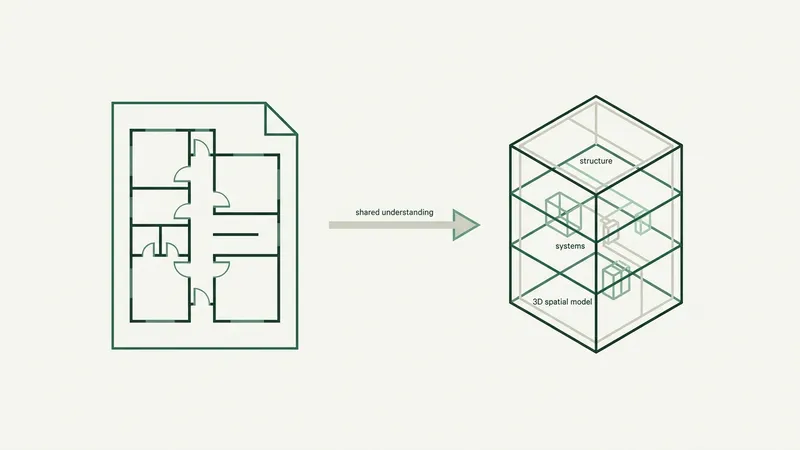
Why off-the-shelf generative AI was not enough — and what actually works for technical drawings
The Data Problem No One Talks About
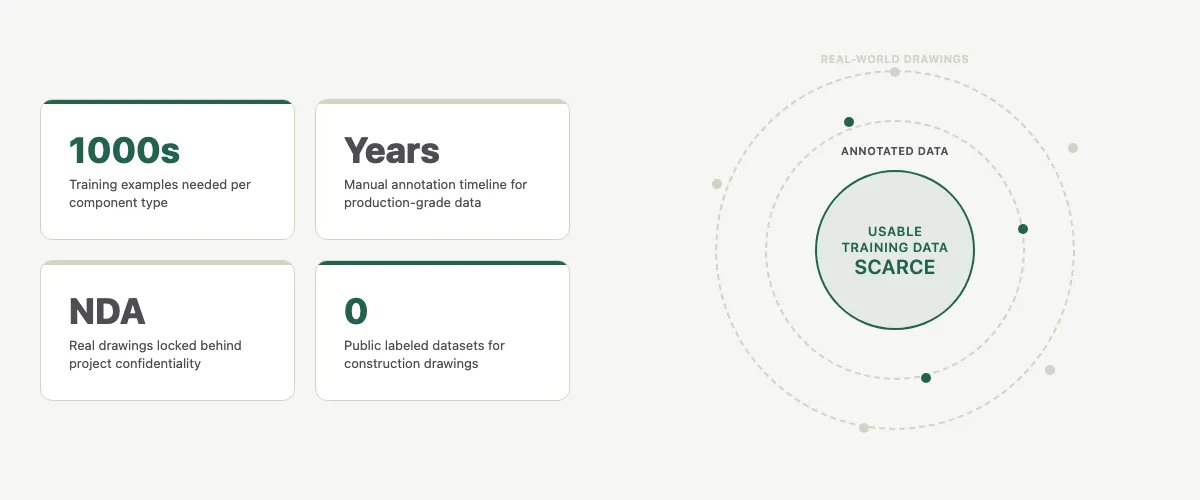
Training AI to read construction drawings sounds simple — until you realize how little labeled data exists.
At Boon AI, we build computer vision models that automatically identify components on construction blueprints — ducts, fittings, fixtures, and dozens of other elements that estimators spend hours counting by hand. Our models need to see thousands of examples to learn what these components look like across different drawing styles, scales, and contexts.
The catch? Manual annotation is painfully slow. Building a dataset large enough for production-grade AI through manual labeling alone would take years. That is not a viable path.
So we turned to synthetic data — generating our own training data at scale. That journey taught us some hard lessons about what actually works when your domain demands precision.
Why Off-the-Shelf Generative AI Is Not Enough
The generative AI techniques making headlines — the technology behind DALL-E, Midjourney, and similar tools — are built for visual content. They excel at producing images that look right.
But construction drawings are not visual content. They are engineering documents where every line, symbol, and connection carries precise meaning. Looking right is not the same as being right.
When we evaluated generative approaches for our training pipeline, the outputs consistently fell short of the structural accuracy our models require. Visually plausible drawings with incorrect engineering relationships do not just fail to help — they actively corrupt training data.
This is a fundamental mismatch. These tools were designed for domains where approximate fidelity is sufficient. Technical drawings demand exactness.

Our Approach: Engineering-First Synthetic Data
Instead of trying to adapt visual generation tools to a precision domain, we built a synthetic data pipeline purpose-designed for construction drawings from the ground up.
The core principle: encode the domain knowledge directly. Rather than hoping a model will learn engineering rules from pixels, we build the rules in. Every generated drawing is structurally valid by construction — which means every annotation is guaranteed accurate.
Why This Works
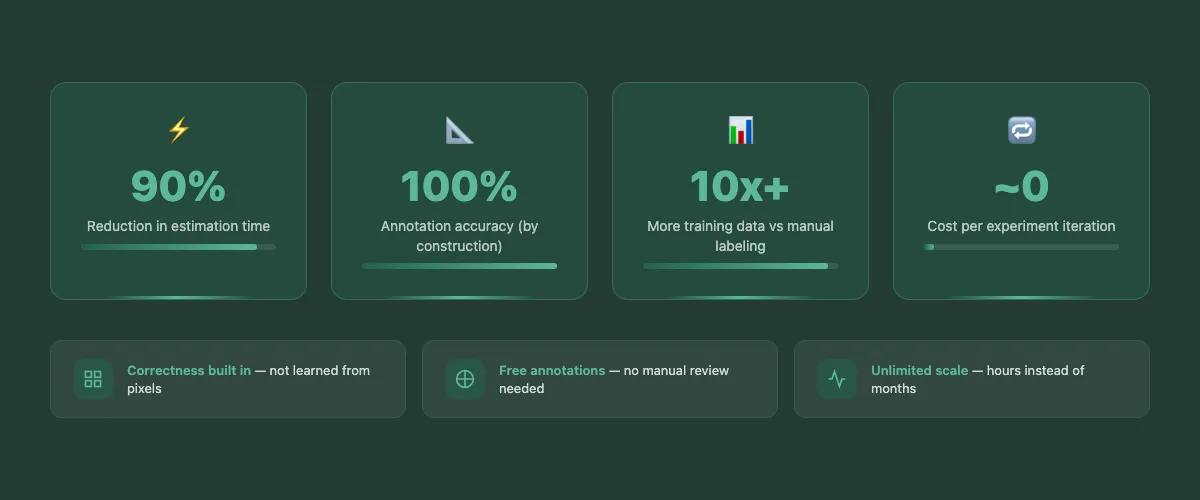
- Correctness is built in, not learned. Components are placed according to real engineering constraints, so the training data never contains structural impossibilities.
- Annotations are free. Because we control the generation process, labels come automatically — no manual review, no human error.
- Scale is unlimited. We can generate massive, diverse datasets in hours rather than months.
- Iteration is fast. The cost of running experiments approaches zero, so we can continuously improve our models.
This approach lets us train on orders of magnitude more data than would be feasible through manual annotation — with higher annotation quality.
What Synthetic Construction Drawings Actually Look Like
Theory is one thing. Here is what the pipeline actually produces.
The drawings below are fully synthetic HVAC plans generated by our system. Each one layers ductwork, fittings, transitions, flex connectors, and diffusers onto realistic architectural floor plans — complete with room labels, column grids, doors, and wall assemblies. Everything you see was generated programmatically. No human drew any of it.
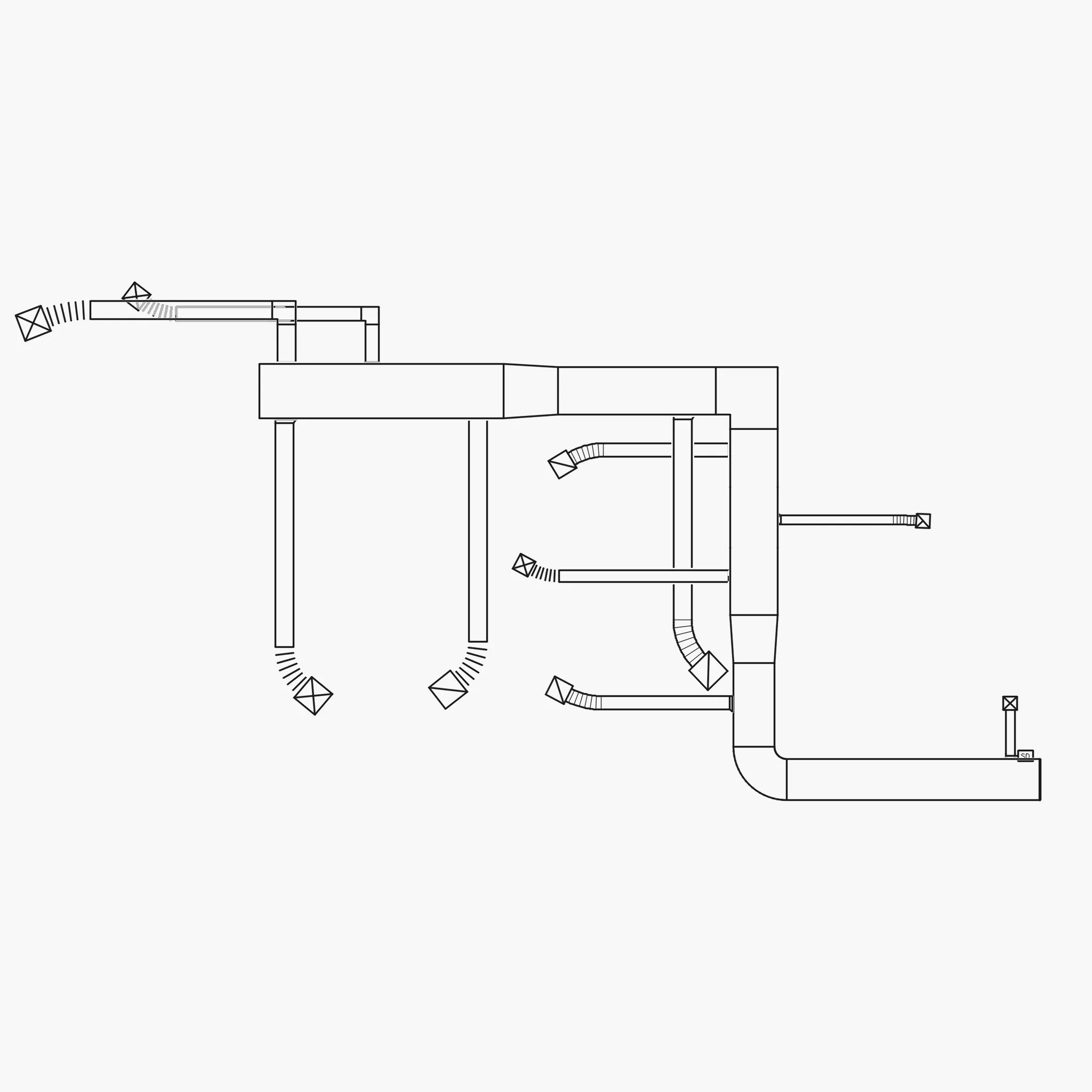
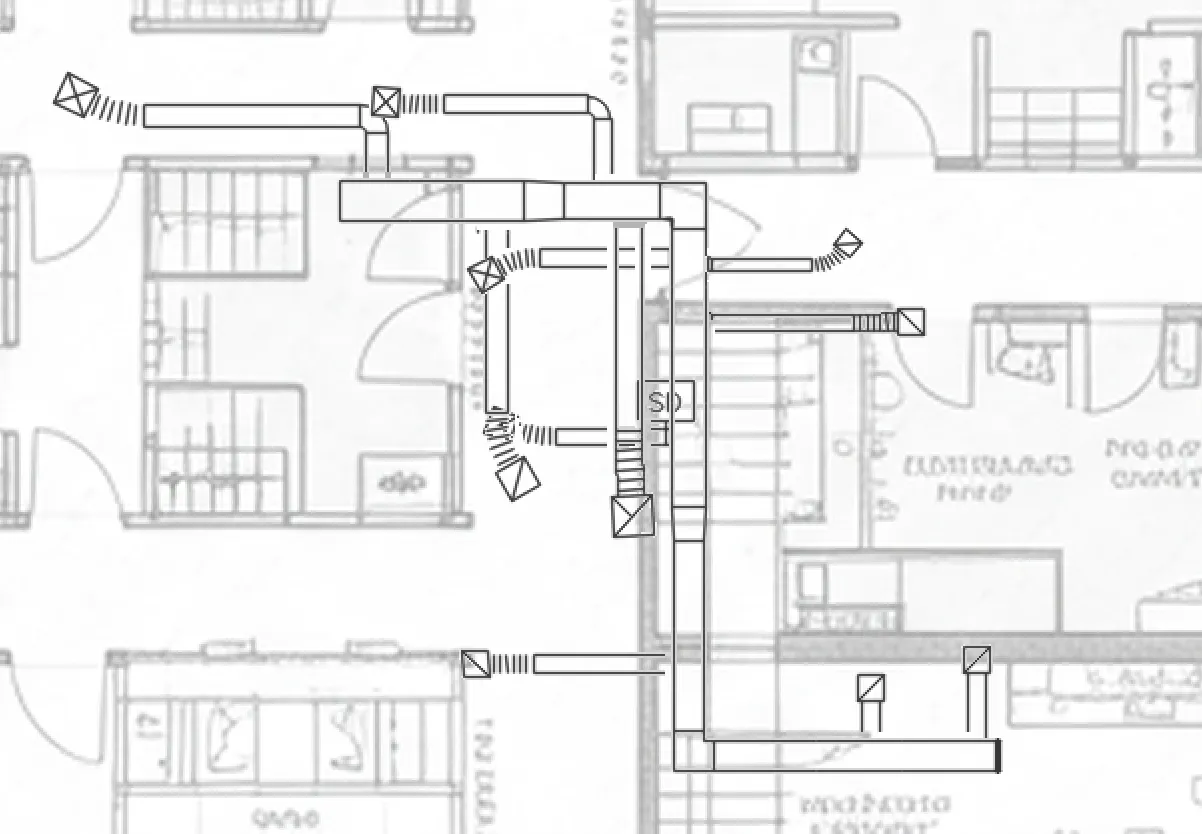
Left: A synthetically generated retail floor plan showing HVAC duct runs with supply diffusers, flex connectors, and duct transitions. Right: A more complex routing layout with curved duct transitions, multiple diffuser sizes, and ductwork spanning admin areas, storage rooms, and corridors. Both drawings were generated programmatically with real engineering constraints and annotated with keyed notes, just like real engineering documents.
Every component in these drawings carries a precise label — duct type, fitting category, connection point — generated automatically by the pipeline. That is thousands of perfectly annotated training examples, produced in minutes rather than months.
Why This Matters for Construction
The construction industry has been underserved by AI in part because the data problem seemed intractable. Real annotated construction drawings are scarce, expensive to produce, and locked behind NDAs and project confidentiality.
Synthetic data changes that equation. It removes the data bottleneck entirely, letting teams focus on what matters: building models that actually help estimators work faster and more accurately.
At Boon, this is the foundation of our automated takeoff system — and it is a key reason we can deliver 90% time savings on estimation work.
Boon AI automates construction takeoffs with AI, reducing estimation time by 90%. Learn more at getboon.ai.