A customer of ours cut their Salesforce license footprint by sixty percent last quarter. They didn't switch CRMs. They built a thin Claude-powered workflow on top of their own data and stopped paying for the seats they used to need.
Salesforce is fine. The bill just thinned out.
I've been turning that over for a few months. Not because I think Salesforce is in trouble, but because of what it says about the rest of the software stack. If a horizontal model plus a weekend of engineering can hollow out the application layer from above, then a lot of vertical AI companies have a durability problem they haven't yet priced in.
We're one of those companies, on most days.
So the question I've been sitting with, on and off, since the start of the year is what actually makes a vertical AI company durable across the next decade of horizontal shipments. The honest answer I've arrived at is that no single moat survives. You need three, and the way the three reinforce each other matters more than any one of them.
This isn't a manifesto. It's the framework I use when I look at our own roadmap on a Sunday and ask whether we're still building the right company. I'll walk through how I got there.
One moat
For most of the last decade, one moat was a complete answer. Procore won on network effects. Veeva won on a proprietary data category. Shopify won on embedded distribution. The model layer wasn't commoditized. The incumbents were slow. One angle was enough.
That stopped being true sometime last year. Frontier models now ship on a six-month cadence. Open-weights catch up six months behind that. Every horizontal vendor has shipped, or is about to ship, agents that reach into the customer's data directly. In that environment, a single moat has a half-life.
The ways single-moat companies fall over aren't theoretical. We've watched it happen to peers in the last eighteen months. A vertical AI company with a great model and no proprietary data watches its technical edge melt the next time a frontier lab trains on overlapping data. A company with a beautiful dataset and no model edge gets undercut when a horizontal lab fine-tunes a frontier model on the same kind of data and prices it at half. A company embedded in a customer's workflow but with no architectural advantage discovers, when a better-funded competitor ships, that the switching cost was always social.
We've spent a lot of evenings asking ourselves which of those three failure modes could come for us. The answer, when you stress-test it honestly, is all three could. The question is just which one comes first.
Technical

What keeps a model durable isn't a benchmark number. Benchmark numbers compress. They're the kind of edge that survives until somebody else trains on more data with a better recipe.
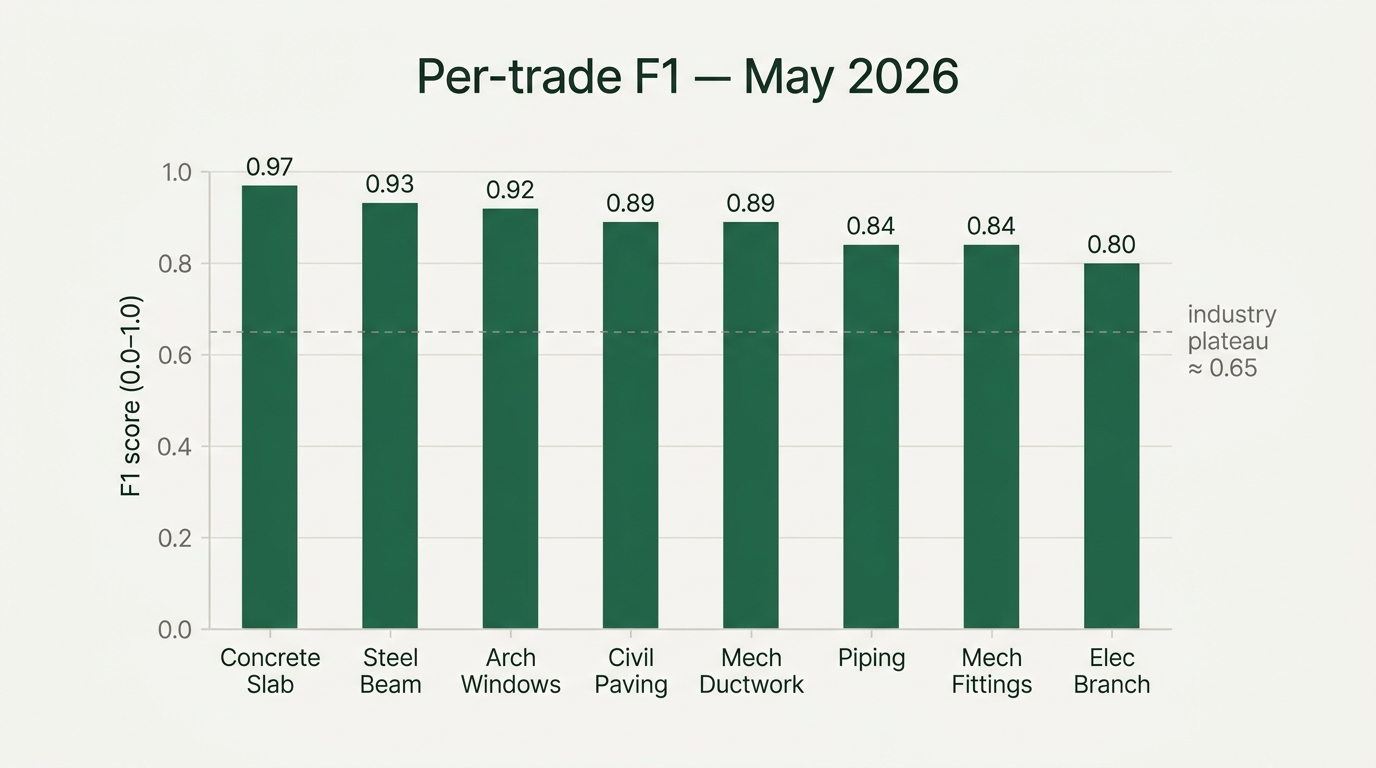
The durable technical edge is the architecture. And architecture is mostly the kills.
We've spent more than one quarter chasing approaches that looked clean on paper and broke on real drawings. Each time we've had to walk something back, the lesson hasn't been that the idea was wrong, exactly. It's been that we underestimated how unforgiving the domain is. In a world where a customer notices a small error, the bar for what counts as working is higher than we expect coming in. Each kill cost us time and taught us something about what construction actually needs from a model. It isn't a better patch-classifier. It's something that can hold a building in its head while it reads a drawing, and reason about what's connected to what. That has shaped the way we've built since.
A horizontal lab waking up tomorrow and deciding to build a construction foundation model doesn't start at zero. They start at minus four years, and they have to rediscover the architectural decisions we've already made and corrected. None of that learning is in any paper. It's in our commit history.
This is a moat. It's also a time-bounded one. A better-resourced lab with the right data can rebuild the architecture in eighteen months. Which is why the second moat exists.
Data
A lot of the AI discourse assumes horizontal labs always have more data than verticals because they have the internet.
In construction, the internet is mostly empty.
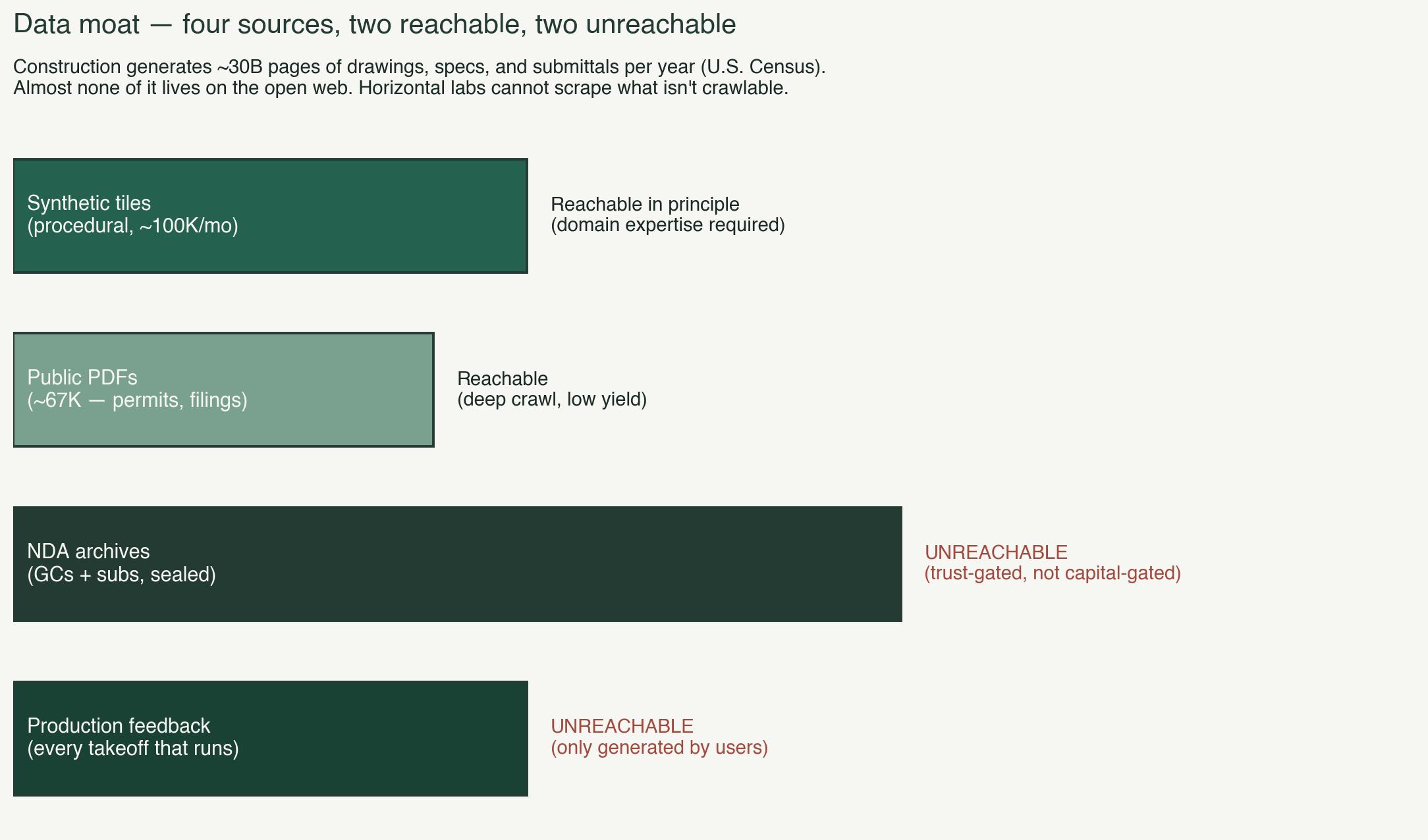
The drawings that teach a model to do real work live in NDA archives at general contractors, in subcontractor records, in permit offices that rate-limit downloads, on local servers in preconstruction trailers. The U.S. Census Bureau estimates the industry generates roughly thirty billion pages of drawings, specs, and submittals a year. Almost none of it is crawlable. None of it shows up in Common Crawl. None of it is on GitHub.
The corpus we've assembled over four years has four layers, and the value is in the stack.
A synthetic layer we generate ourselves, deterministic and labeled by construction. We didn't get here on the first try, and we've learned the hard way that synthetic data done badly is worse than none.
A public layer assembled from permit portals, government filings, and published standards. Small next to the web. Meaningful inside one industry.
NDA archives from contractors and subcontractors who agreed to train with us in exchange for early access to the model. An ENR top-50 electrical contractor's archive. A national general contractor's spec templates. More under negotiation. Each one of these takes six months of trust-building and one of them is worth more than a year of synthetic generation.
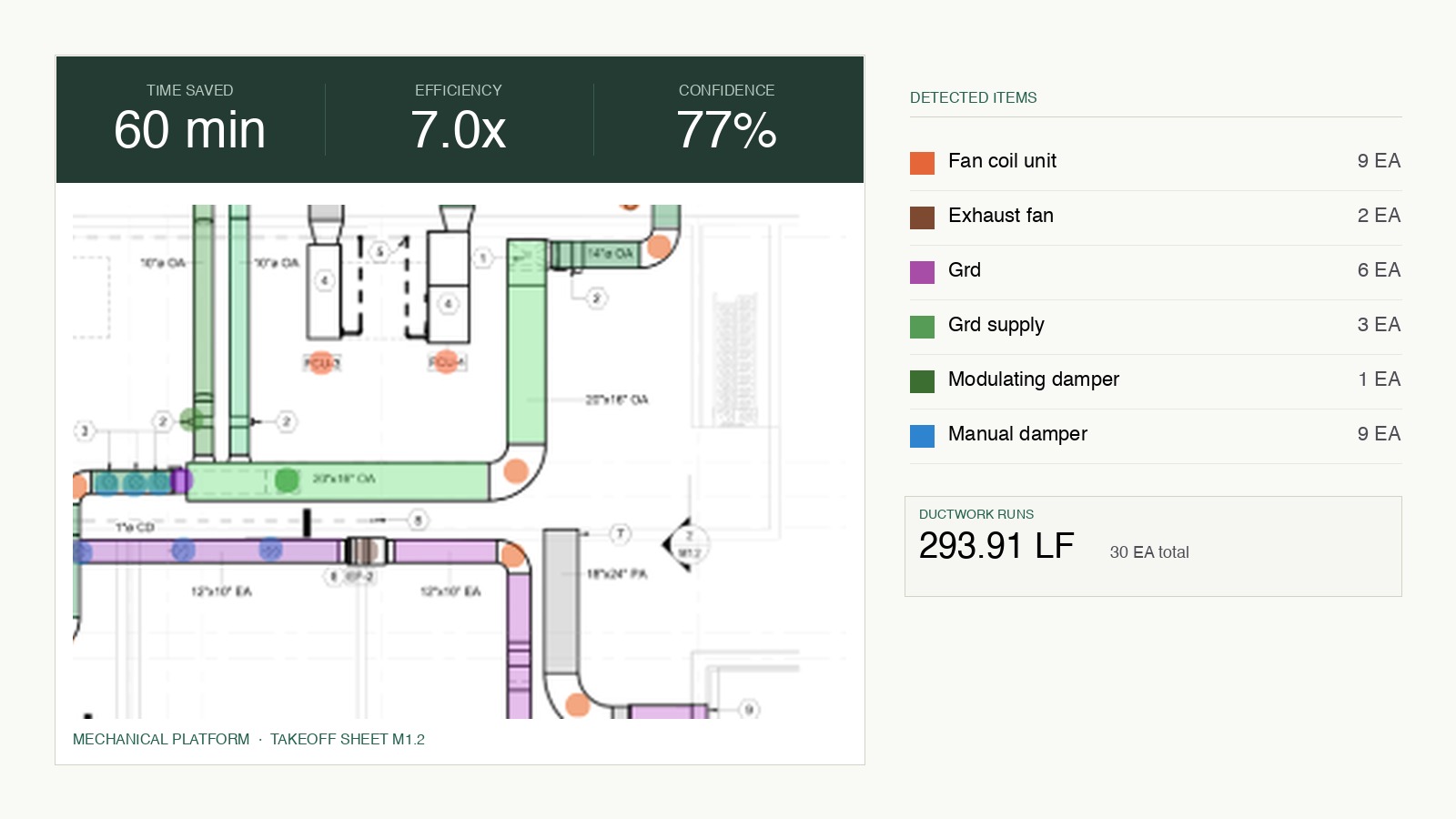
And production feedback. Every takeoff that runs on the platform sends structured signal back into training: corrections, confirmations, scope adjustments, missing-element flags that turned out to be real. That feedback is what makes the synthetic generator targeted instead of random.
None of the four layers is the moat by itself. The stack is. Someone starting on this today would face the part of the problem that doesn't yield to capital. The archives take years of trust-building to surface. The production feedback loop takes a real user base to populate. None of that is purchasable, and most of it is invisible until you've tried.
A data moat alone, like a technical moat alone, doesn't protect you. Without the model, data is inventory.
Operational

The third moat is the one technology-first companies underweight, including us for longer than I'd like to admit. It's the moat of where the software actually lives in the customer's environment, and whose name is already on the contract.
Construction data is radioactive by contract. Sealed bid sets carry owner-level confidentiality. Federal jobs carry CUI handling requirements. Many subcontractor agreements explicitly prohibit third-party cloud handling of bid-sensitive information. So we deploy a Mac Mini into the preconstruction office with our full inference stack running locally. The sealed plan set is read, processed, and priced without leaving the GC's network. The cloud only sees training signal, never the drawings.
This wasn't a product decision so much as a constraint we had to design around. The compliance boundary was already there. We had to build a stack that respected it before we could have any of the other conversations.
The agent lives inside Microsoft Teams. Every piece of construction software written in the last twenty years has died the same death: estimators stop logging into the dashboard by week three. Logging in is the failure mode. The one application a preconstruction department actually uses every day is Teams. So we stopped building a dashboard and started building a Teams-native agent. An estimator types a message. The takeoff runs. The BOM comes back in the thread. There's no new app, no new login, no change management budget. Every new capability we ship is a new message type, not a new install.
That distribution choice does the adoption work that no amount of product polish would have done.
And the logos are doing their own quiet thing. More than twenty of ENR's top 100 GCs are deployed or in active pilots. Each one accelerates the next. Each one feeds new signal into the data layer. Each one makes the relationship graph harder to break into. It's the least exciting moat to put on a slide and, I suspect, the one that's going to matter most five years from now.
Why three
Each of the three, on its own, has a familiar failure mode. A technical edge without the data starves. A data edge without the model sits in a warehouse. An operational footprint without either is a relationship we eventually disappoint.
Stacked, they compound. The model gets better on the data. The data gets sharper through production feedback. The operational footprint earns more archives through more logos, which trains a better model, which drives more deployments. When one of the three weakens, the other two pull harder. If a frontier lab closes the technical gap, the data and operational moats slow substitution long enough to recover. If a customer is poached, the production feedback loss is a small fraction of the total. If a synthetic technique fails, the production feedback path keeps the flywheel turning.
A single moat is brittle. Two are better. Three, reinforcing each other, is the only structure I've seen hold up when I stress-test it against the next eighteen months of horizontal shipments.
I can't promise we'll get all three right. We've gotten each of them partially wrong before, and we will get each of them partially wrong again. The work isn't to settle on the right moats and defend them. It's to keep checking, quarter by quarter, whether each one is actually pulling its weight, and whether the other two are reinforcing it the way the theory says they should.
Most of the time, the honest answer is partly. Which is uncomfortable, and probably correct.
Deepti Yenireddy is the founder and CEO of Boon AI.